

















——對抗式學習
李宏毅∕現為臺大電機系助理教授,研究興趣是以機器學習技術讓機器辨識並理解語音訊號的內容。在 YouTube 頻道上找到更多和機器學習相關的教學影片(請見延伸閱讀)。
近年來,隨著人工智慧的發展,機器的能力越來越強,相關技術已經進入我們的生活中,例如當我們上傳一張照片到臉書時,臉書可以精確地找出照片中的人臉,而 iPhone 甚至可以知道一張臉是不是他的主人。然而,今日機器較擅長的是從資料中歸納找出通則,例如臉書知道人臉有那些共同的特徵,所以可以偵測出人臉,但是在能夠歸納後,機器能不能進一步創造呢?例如機器既然知道人臉的特徵,能不能進一步畫出人臉來呢?讓機器具備創作的能力是近年備受重視的研究領域,今天我們要來談一談其中備受矚目的技術──對抗式學習(adversarial learning)。
對抗式學習
創作的挑戰在哪裡?機器的創新是從模仿開始,當機器學習寫詩時,我們會給它一堆詩人的詩句;學習畫圖時,我們會給它一堆畫家的作品,機器可以輕易地把成千上萬的範例硬記下來,但是要如何讓機器可以自出機杼,而不是抄襲它看過的範例呢?以下我們以學習創作二次元人物頭像為例,來看看對抗式學習如何解決上述問題。
在對抗式學習中,需要兩個由機器扮演的角色,一個是生成者(generator),生成者的工作就是創作二次元人物,另一個是鑑別者(discriminator),鑑別者的工作是根據人類提供的範本評價生成者的成果,因為通常生成者和鑑別者都是類神經網路,所以這個技術又稱為生成式對抗網路(Generative Adversarial Network, GAN),生成者和鑑別者這兩個角色會互相砥礪,讓彼此的能力都越來越強。在二次元人物頭像創作的學習過程中,以下是生成者和鑑別者可能的互動情形:
- 生成者一開始根本不知道二次元人物長什麼樣子,所以只是信手塗鴉,他畫出來的圖可能就是一堆雜訊,根本不知道在畫什麼,像是這樣:

▲圖片來源/作者繪製
- 接下來,人類提供大量漫畫家繪製的二次元人物頭像給鑑別者,鑑別者比對生成者繪製的圖片和人繪製的圖片後,會歸納出生成圖片和真實圖片的差異(這是今日機器所擅長的),鑑別者可能會發現真實圖片上都有兩個圓圈(也就是眼睛),不過生成圖片沒有。
- 鑑別者把歸納成果告訴生成者,生成者的目標是希望產生出來的圖會被鑑別者認為是人所繪製,既然鑑別者認為人繪製的頭像上應該要有兩個圓圈,所以接下來生成者畫出的圖就會有兩個圓圈,像以下這樣:

▲圖片來源/作者繪製
- 鑑別者接下來比對生成者新產生的圖片和人繪製的圖片的差異,因為生成者已經學會人臉就是有眼睛這件事,所以用是否有兩個圓圈來判斷是否為人畫的圖片這條規則就不適用了,所以鑑別者需要找出新的規則,例如它可能發現說,生成圖片和人繪製的圖片的差異為是否顏色繽紛。
- 鑑別者再將歸納出來的規則回饋給生成者,生成者就會產生彩色的圖片如下:

▲圖片來源/作者繪製
在鑑別者和生成者互動的過程中,鑑別者會不斷找出生成圖片和人畫的二次元頭像間的差異,因為鑑別者一直在挑生成者的毛病,而生成者一直在想辦法讓鑑別者找不到毛病,兩者間可以看作是一種對抗的關係,這就是生成對抗網路中的「對抗」一詞的來源,不過實際上生成者和鑑別者之間的關係「寫做敵人,念做朋友」,透過相互砥礪生成者產生的圖畫,就會越來越接近人所繪製的圖畫。在以上學習過程中,人類的工作僅僅為蒐集漫畫給鑑別者看,鑑別者如何進行歸納、生成者如何根據歸納結果進行改進都是人工智慧本來就會做的事,並不需要人類告訴它們該怎麼做。
那為什麼生成者不能自己看漫畫學習,而需要鑑別者的幫忙呢?有了鑑別者的存在,生成者在學習繪圖的過程中,從來沒有看過人繪製的漫畫,他所知道的一切都是鑑別者教的,所以不用擔心生成者會拷貝人繪的圖,而鑑別者教導生成者時教的是大方向(例如:要畫眼睛、要用色彩等),所以生成者在學習時,學的是創作的「神韻」而非僅僅是「模仿」而已。
如果用對抗式學習來讓機器學習畫二次元人物,機器畫出來的人物像什麼樣子呢?圖一都是機器畫出來的人物,是不是很難相信這些圖是機器自行創造出來的呢?雖然本節僅以二次元人物生成為例,但同樣的技術也可以用來進行其它類型的創作,例如:寫詩、寫文章、作曲等。

▲圖一:這是機器透過對抗式學習畫出的二次元人物,是不是根本就可以以假亂真呢?圖片來源/所用技術由臺灣大學吳宗翰、謝濬丞、陳延昊、錢柏均等同學實作

▲圖二:機器按照輸入的指令繪出二次元人物頭像。圖片來源/所用技術由臺灣大學吳宗翰、謝濬丞、陳延昊、錢柏均等同學實作
其實對抗式學習沒有那麼容易……
對抗式學習是一個非常強大的方法,一旦成功,生成者的能力往往令人驚艷,但是對抗式學習卻以容易失敗而聞名。為什麼對抗式學習容易失敗呢?因為在對抗學習的過程中,生成者和鑑別者的「能力」必須要同步,也就是說兩者必須要一直保持棋逢敵手的狀態。如果在學習的過程中生成者「壓制」了鑑別者,也就是說生成者產生的圖片還沒有到以假亂真的程度,但是因為鑑別者的能力不足,已經無法分別生成圖片和真實圖片的差別,那麼生成者就會因為得不到鑑別者的回饋而停止進步,這就好像是研究生問指導教授說:「接下來我有甚麼要改進的?」指導教授說你已經完美,那麼研究生的學習就停滯了。但另一方面,如果鑑別過嚴苛,提出的回饋是生成者現階段無法達成的,生成者不知道要如何達到,那麼學習也會停滯,這就像是碩一新生請指導教授給點方向,教授說:「我認為你下一個目標應該是要拿諾貝爾獎。」學生不知道要怎麼做到,也就無法學習了。如何使得生成者和鑑別者保持在棋逢敵手的狀態,鑑別者一直可以分辨生成者產生的圖片和人畫的漫畫間的差異,但又不至於提出生成者無法達成的要求,是對抗式學習的研究重點,目前尚未完全解決。
可以接收指令的生成者
在前文中我們僅要生成者畫一些二次元人物頭像,畫什麼都好,但事實上我們還可以讓生成者根據輸入的指令產生對應的創作。假設我們希望可以輸入文字(例如「藍髮紅眼」),機器根據輸入的文字畫出擁有對應髮色和瞳色的角色,此時生成者的工作是讀入文字,產生對應圖片,而鑑別者要做兩件事,一方面鑑別者要跟前文一樣看生成者產生的圖片和漫畫的差異,同時,人類還要提供給鑑別者人物頭像和其對應的特徵文字敘述(紅髮、藍眼等),讓鑑別者能夠看生成者輸入的文字和其繪出的圖片是否匹配,避免輸入「藍眼睛」生成者卻畫出綠眼睛的角色。圖二是訓練過後實際上生成者按照指令產生的人物頭像,生成者幾乎可以完全正確按照指示,創造出對應的人物頭像,不過機器還是有失誤的時候,例如輸入指令「藍髮紅眼」時,圖二右上角的人物一隻眼睛是紅的另一隻眼睛卻是藍的,顯然生成者誤以為只要有一隻眼睛是紅的就算是滿足要求,這是機器才會犯的錯誤。
除了根據輸入文字繪製二次元人物外,上述按照指令進行創作的技術還有很多應用,例如:輸入手繪漫畫草稿,生成者可以自動上色(http://paintstransfer.com);我們已經看到了智能修圖軟體的雛形,你可以在網路上找到相關的展示(https://goo.gl/uN7LmD);輸入一張照片,生成者產生影片,讓照片中的人事物動起來(就像是哈利波特的魔法世界中,相片中的人物是會動的,http://carlvondrick.com/tinyvideo/)。以上都是影像相關的應用,對抗式學習的應用不只如此,輸入文字,讓生成者產生回應的語句,我們就有了聊天機器人(https://arxiv.org/abs/1701.06547);輸入一段有雜訊的語音,生成者還原回乾淨的語音,就可以增進語音助理的語音辨識正確率(https://arxiv.org/abs/1703.09452)。
再加入還原者
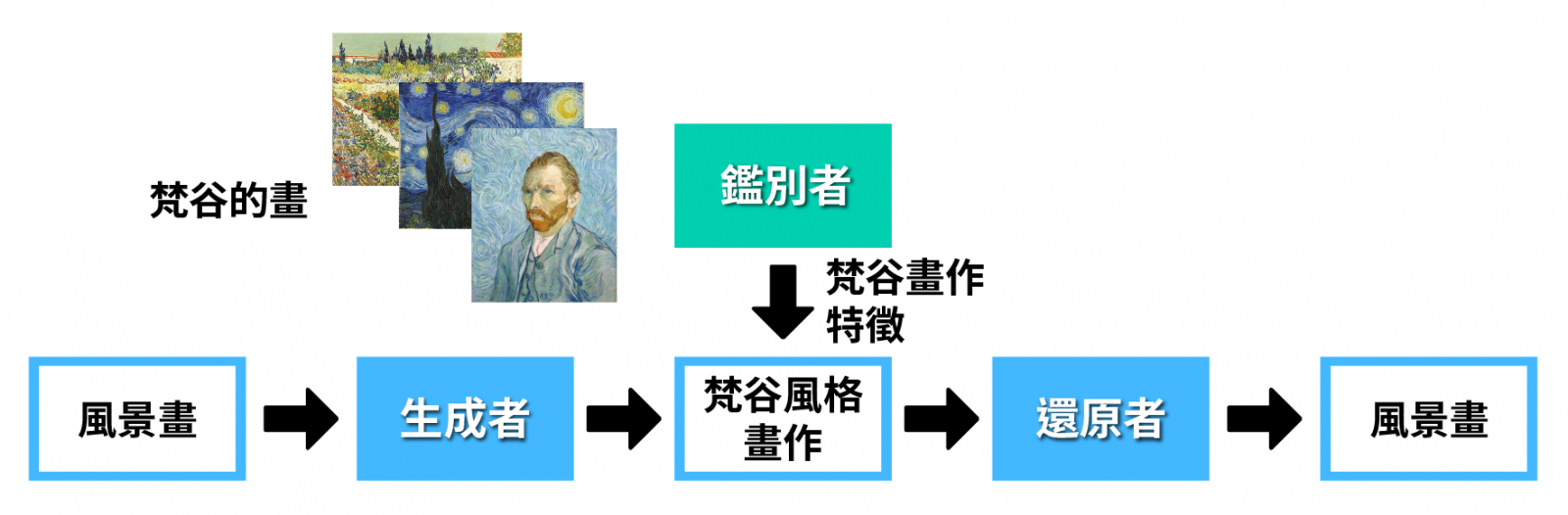
▲圖三:循環生成式對抗網路基本原理,此處希望生成者可以學會把風景照以梵谷畫風重新繪製。鑑別者看過很多梵谷的畫作,它可以告訴生成者梵谷畫作的特徵;還原者將生成者的輸入還原;生成者有兩個目標,它一方面要使得產生出來的圖片讓鑑別者認為像是梵谷畫作,另一方面又要讓還原者可以將其輸出還原。
我們現在設想另外一個任務,我們希望給生成者一張風景照,生成者把風景照以梵谷畫風重新繪製,人類可以輕易蒐集到一堆梵谷的圖給鑑別者看,由鑑別者找出梵谷圖畫的特徵,再把學到的特徵教給生成者,讓生成者學到產生有梵谷風格的圖,但生成者產生的圖可能會跟輸入沒有任何關連性,例如輸入是一張風景畫,但輸出可能是人物自畫像(雖然這張自畫像可能很像梵谷畫的),這種狀況不是我們所期待的。如果今天我們可以給鑑別者一些一般風景照和對應的梵谷作品,鑑別者就可以去看生成者輸入的風景照和輸出的梵谷風格作品是否有正確對應關係,進而教導生成者,但問題是在一般情況下,給一張風景畫(例如:日月潭),世界上根本找不到一張對應的梵谷作品(梵谷當然沒畫過日月潭),怎麼辦呢?這時我們就需要新的技術,這個技術叫做循環生成式對抗網路(Cycle GAN),循環生成式對抗網路的基本原理請見圖三。在循環生成式對抗網路中我們需要引入第三個角色──還原者(reconstructor),還原者的工作是把生成者的輸出還原回輸入的原圖,生成者和還原者是合作的關係,生成者必須要產生還原者可以還原的圖片,如果生成者的輸入是海景、輸出很無厘頭地是自畫像,還原者只看到自畫像,根本不可能猜出原來輸入的是海景,就會無法還原,生成者要幫助還原者還原,那就不會輸出和輸入完全無關的東西。
用上述技術我們可以把筆者的人臉做各種轉換,結果如圖四所示,讓鑑別者看女性照片,鑑別者會找出女性共同特徵,使得生成者的輸出會把照片中的人物女性化(但又因為還原者的存在,生成者並不會輸出完全不相干的女性,而是修改照片中的人物),根據圖四的結果,顯然鑑別者學到一些對女性的刻板印象,它認為化妝和長髮是女性的特徵,所以圖四第二列上面的兩張圖被加上腮紅、下面的兩張圖變成長髮。用同樣的技術,給鑑別者看老人的照片,就可以讓生成者學會把輸入的照片中的人物加上皺紋,給鑑別者看一堆金髮人物的照片,就可以把人物變金髮。
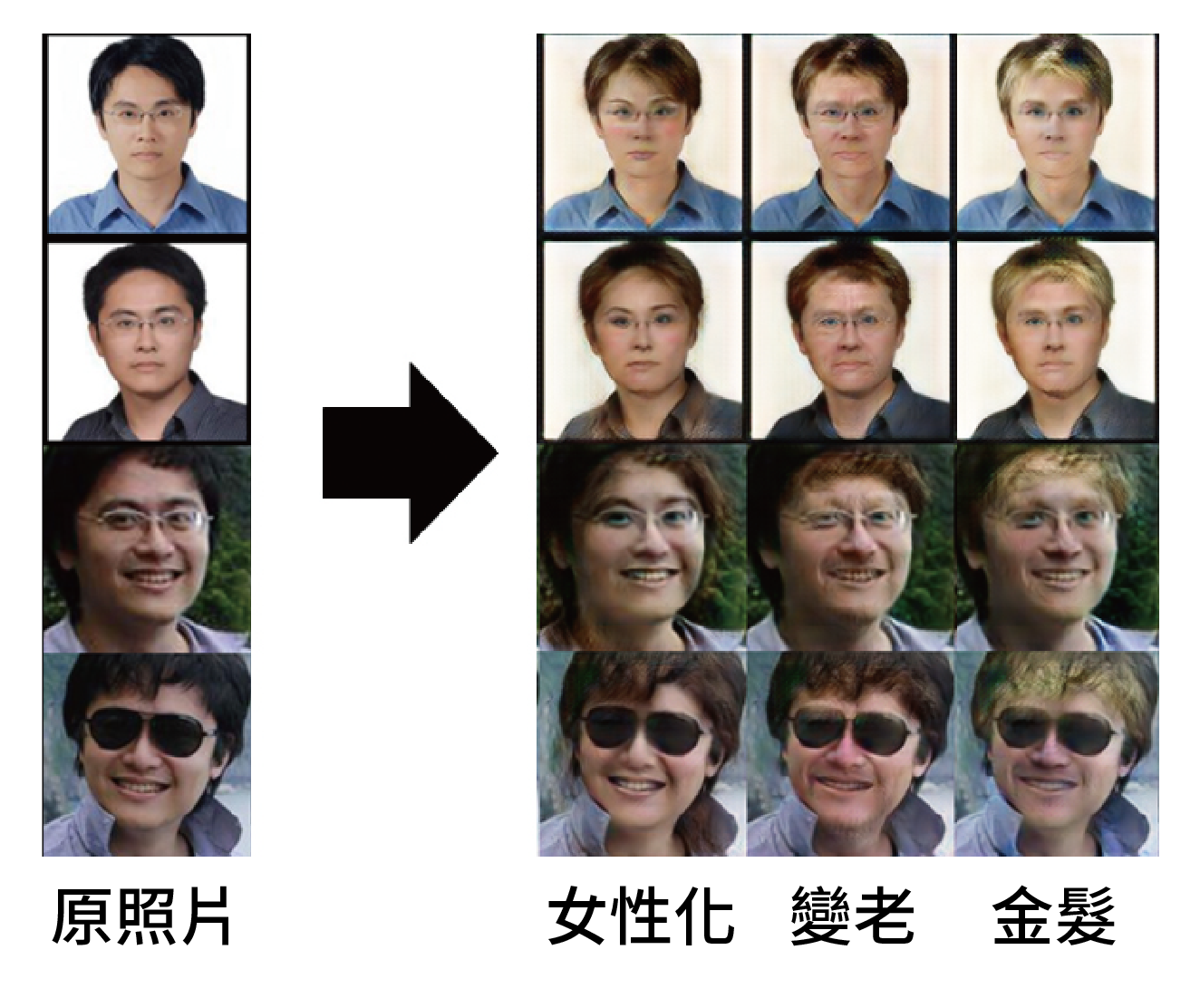
▲圖四:將筆者照片做各種轉換。圖片來源/所用技術由臺灣大學吳元魁同學實作
以上講的是影像相關的技術,類似技術也被用在文字上,例如給鑑別者一堆正面的句子,我們就可以自動學出一個生成者,可以將輸入語句轉為正面語句,圖五是生成者實際學出來的成果,這個技術有什麼用呢?如果你的主管講話刻薄,你就可以在耳機中裝這個系統,你的人生就會過得比較愉快。這個技術也被用在翻譯上,傳統的翻譯系統,需要人教機器說「Good morning」的中文翻譯是「早安」、「Good afternoon」的中文翻譯是「午安」等,但是現在有機會只要一堆 A 語言的語句、一堆 B 語言的語句,不需要人去標註兩種語言間的對應關係,用類似循環式對抗的技術,翻譯居然也可以達成(https://arxiv.org/abs/1711.00043)。相關的技術也可以用在語音上,只要蒐集一堆男聲,鑑別者就可以找出男聲的特徵,讓生成者輸入一段女聲後輸出一段內容一樣的男聲(因為還原者的存在,會讓輸入和輸出所講的內容相同,只是聲音改變),同理,只要蒐集一堆女聲,透過鑑別者和還原者,就可以讓生成者學會輸入一段男聲轉成內容一樣的女聲,這樣就可以做出變聲器了(https://goo.gl/GWeWYH)。

▲圖五:機器可以把輸入文句轉成正面的句子,左側的負面文句為人類的輸入,右側的正面文句為機器的輸出。圖片來源/所用技術由臺灣大學王耀賢同學實作
增強式學習與對抗式學習
自從有了 AlphaGO 以後,街頭巷尾都在討論增強式學習(reinforcement learning),其實增強式學習和對抗式學習是非常有關係的。在增強式學習中,機器要和環境互動,互動過程會得到回饋(reward),機器會自行學習如何得到最大回饋,以圍棋為例,環境就是機器的對手(可能是真人也可能是另一台機器),透過和對手不斷地對弈,機器會自行學習如何獲勝。增強式學習和對抗式學習在演算法上其實有很多類似之處,增強式學習是機器和環境互動,而對抗式學習是生成者和鑑別者互動,不同之處在於在增強式學習的演算法中,一般假設環境不會隨時間改變,但對抗式學習更複雜,生成者和鑑別者兩者皆會持續進步。雖然現今在研究上增強式學習和對抗式學習仍然是兩個社群,但是因為有很多概念是共通的,所以未來這兩個領域的各種訓練技巧可以互通有無。
結語
對抗式學習發展迅速,新技術不斷推陳出新,有興趣深入研究的讀者可以在網路上找到「生成對抗網路動物園(GAN Zoo,https://goo.gl/XJUUS3)」,在筆者寫本篇文章的期間(2018年1月),動物園中已經蒐錄了至少 250 種以上不同的生成對抗網路變型,對抗式學習顯然是下一個人工智慧研究的熱點,為人工智慧帶來新的想像。
延伸閱讀
1.Youtube, NIPS 2016 - Generative Adversarial Networks - Ian Goodfellow, https://goo.gl/AjSBgf.
2. 李宏毅 YouTube 頻道,https://goo.gl/ciR7m2。
人工智慧浪潮下的數學教育:下一篇⇢



