

















人工智慧的核心技術與未來
曲建仲/臺灣大學電機工程學系博士,政治大學科技管理與智慧財產研究所兼任助理教授,曾榮獲中華民國 96 年度全國優秀青年工程師獎章並獲總統召見,致力臺灣科技教育多年,擅長以淺顯易懂的文字由淺入深帶領非理工背景的讀者們了解艱深困難的科技原理。
人工智慧(Articial Intelligence, AI),一個吸引人們卻又教大家害怕的名詞,吸引我們的是一個會思考、可以協助人們處理工作,可以替我們帶小孩洗衣做飯的智慧型機器人;讓我們害怕的是這個機器人自己會思考,哪天他不聽話了怎麼辦?更慘的是,哪天老闆發現他比我還好用,那我不就失業了?許多人以為人工智慧就是科幻電影裡會思考的機器人,人工智慧真的這麼神奇嗎?現在的人工智慧到底發展到什麼程度了?它到底有那些限制呢?
人工智慧的定義與範圍
人工智慧是指人類製造出來的機器所表現出來的智慧,其討論研究的範圍很廣,包括:演繹、推理和解決問題、知識表示法、規劃與學習、自然語言處理、機器感知、機器社交、創造力等,而我們常常聽到的「機器學習(machine learning)」是屬於人工智慧的一部分,「深度學習(deep learning)」又屬於機器學習的另一部分,如圖一所示。
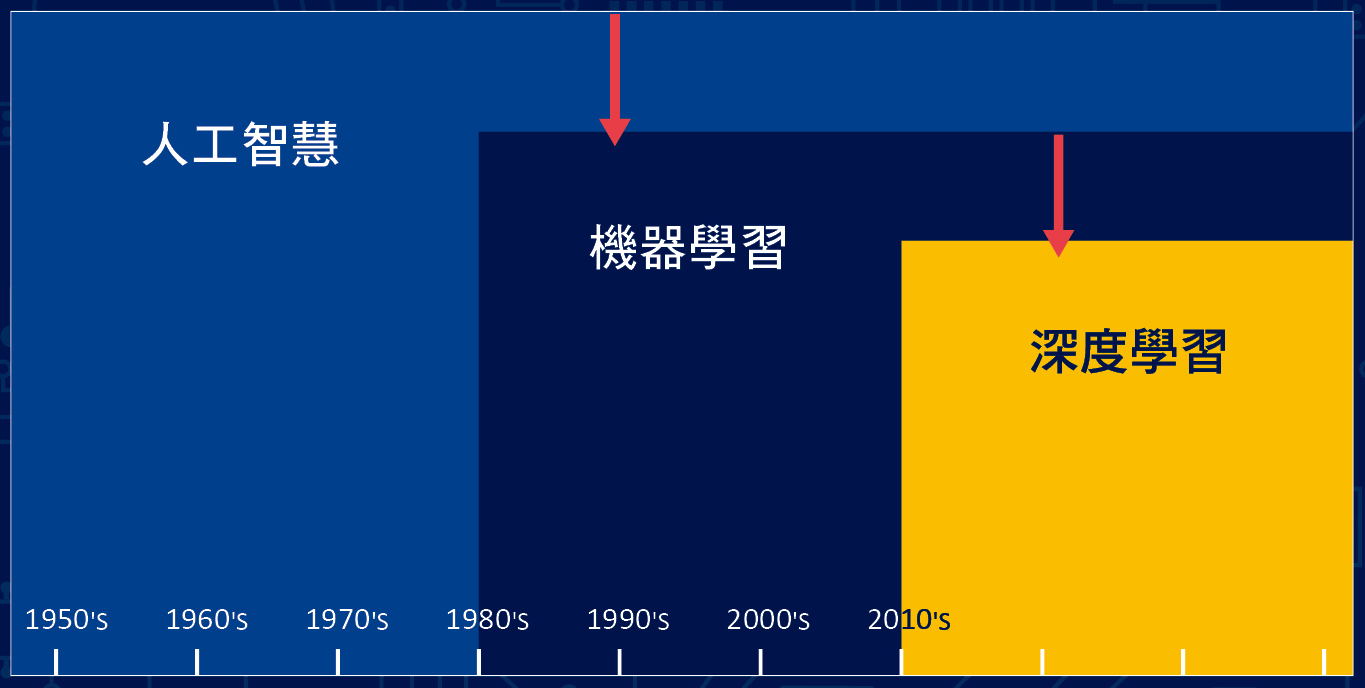
▲圖一:人工智慧、機器學習、深度學習的範圍。參考資料/blogs.nvidia.com.tw
人工智慧的依照機器(電腦)能夠處理與判斷的能力區分為四個分級如下:
AI 發展進程──人工智慧的歷史與分級
第一級人工智慧(first level AI):自動控制
第一級人工智慧是指機器(電腦)含有自動控制的功能,可以經由感測器偵測外界的溫度、濕度、亮度、震動、距離、影像、聲音等訊號,經由控制程式自動做出相對的反應,例如:吸塵器、冷氣機等,這個其實只是電腦含有自動控制的程式,程式設計師必須先把所有可能的情況都考慮進去才能寫出控制程式,算不上是真的「智慧」。
第一級人工智慧就好像是公司裡的工讀生:只是執行老闆交待的命令,進行各種重複性的工作,並不會去思考這個命令是否正確,例如:老闆說把大箱子搬到寫有「大」的區域;小箱子搬到「小」區域,工讀生就依照老闆的交待去做。
第二級人工智慧(second level AI):探索推論、運用知識
第二級人工智慧是指機器(電腦)可以探索推論、運用知識,是基本典型的人工智慧,利用演算法將輸入與輸出資料產生關聯,可以產生極為大量的輸入與輸出資料的排列組合,可能的應用包括拼圖解析程式、醫學診斷程式等。
第二級人工智慧就好像是公司裡的員工,能夠理解老闆交待的規則並且做出判斷,例如老闆說根據箱子長、寬、高分類大小箱子,運用知識留意不同貨物種類:小心易碎、易燃物品,員工就依照這個意思把箱子的尺寸量出來分類,並且要判斷什麼貨物「易碎」或「易燃」。
第三級人工智慧(third level AI):機器學習
第三級人工智慧是指機器(電腦)可以根據資料學習如何將輸入與輸出資料產生關聯,「機器學習」是指根據輸入的資料由機器自己學習規則,可能的應用包括搜尋引擎、大數據分析等。
第三級人工智慧就好像是公司裡的經理,能夠學習原則並且自行判斷,例如老闆給予大箱子與小箱子的判斷原則(特徵值),讓經理自己學習如何判斷多大是大箱子?經理就依照以往的經驗,自己思考多大的箱子是「大」?
第四級人工智慧(fourth level AI):深度學習
第四級人工智慧是指機器(電腦)可以自行學習並且理解機器學習時用以表示資料的「特徵值」,因此又稱為「特徵表達學習」,可能的應用包括:Google 教會電腦貓的特徵。第四級人工智慧就好像是公司裡的總經理,能夠發現規則並且做出判斷,例如:發現有一個箱子雖然很大但是卻是圓形(特徵值),與其他貨物不同應該另案處理。
第三級(主要是指機器學習)與第四級(主要是指深度學習)不容易區分,其實深度學習是由機器學習發展而來,主要的差別在於,第三級人工智慧處理資料時的「特徵值」必須由人類告訴機器(電腦);第四級人工智慧處理資料時的「特徵值」可以由機器(電腦)自己學習而得,這是人工智慧很大的突破。
人工智慧的歷史
自從人類發明了第一台電腦,就開始了人工智慧相關的發展,到現在已經超過半個世紀,其間經歷過三次熱潮,之前每次都因為某些技術上的困難無法突破,我們先來介紹一下人工智慧發展的歷史,以及每一次熱潮興起的原因與遭遇的困難。
第一次熱潮(1950~1960 年):
由 1950 年代開始發展,主要是利用電腦針對特定問題進行搜尋與推論並且予以解決,但是當時的電腦計算能力有限,一遇到複雜的問題就束手無策,被戲稱為只能解決玩具問題的人工智慧,因此到了 1960 年代就冷卻了下來。
第二次熱潮(1980~1990 年):
由 1980 年代開始發展,主要是把大量專家的知識輸入電腦中,電腦依照使用者的問題判斷答案,專家系統應用在疾病診斷,連續的問題有一個判斷錯誤則得到錯誤的結果,而且知識是無窮無盡的,不可能把所有的知識都輸入電腦,還把所有知識的前後順序都找出來,因此最後變得不實用,到了 1990 年代又冷卻了下來。
第三次熱潮(2000 年~現在):
由 2000 年代開始發展,由於半導體技術的進步提升了很大的運算能力,而且半導體成本的下降使用雲端儲存變得便宜,在雲端伺服器內收集了世界各地的「大數據(big data)」,為人工智慧建立了很好的發展基礎,其中機器學習是經由大數據來訓練電腦「學習」資料的特徵值;深度學習是經由大數據來訓練電腦自行「理解」資料的「特徵值」,稱為「特徵表達學習」。
由於半導體技術的進步與成本的下降,使得大量數據的儲存與運算變得容易,提供了人工智慧極佳的發展環境,依照目前整個科技產業的發展,我們不必擔心這一次的人工智慧會有冷卻的一天,相反的,應該擔心人工智慧的過度發展,會不會有一天對我們造成負面的影響。
AI背後強大的處理器──人工智慧的雲端與終端
網際網路是一個開放的空間,由數以億計的電腦主機與伺服器連結而成,如圖二 (a) 所示,要如何描述這麼多電腦主機與伺服器架構而成的系統呢?因此科學家們使用「雲端(cloud side)」這樣的名詞來代表這個系統,相對於使用者所在的「終端(edge side)」,如圖二 (b) 所示。
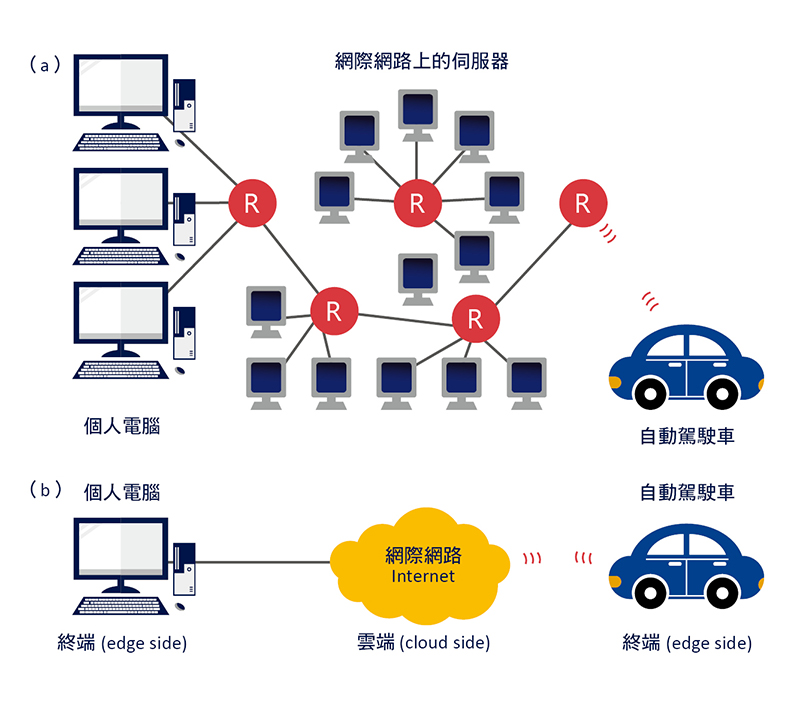
▲圖二:人工智慧的雲端與終端示意圖。
人工智慧大量的學習與運算目前都借助於雲端伺服器強大的處理器來進行,早期使用 Intel 的「中央處理器(central processing unit, CPU)」,後來科學家發現 Nvidia 的「圖形處理器(graphics processing unit, GPU)」效能比 CPU 高 10 倍以上,Intel 經由併購 Altera 取得「可程式化邏輯陣列(field programmable gate array, FPGA)」技術來與 GPU 抗衡,另外有更多的廠商開發始發展「特定應用積體電路(application specic integrated circuit, ASIC)」,例如:Google 自行設計的「張量處理器(tensor processing unit, TPU)」或 Intel 自行設計的「視覺處理器(vision processing unit, VPU)」,就是一種針對人工智慧這種「特定應用」所開發的積體電路,以上這些處理器都是裝置在「雲端」。然而並不是所有的應用都適合把大數據傳送到雲端處理,例如:自動駕駛車必須在車上「終端」進行處理才能即時反應道路情況。
蘋果公司這次(2017 年)推出的 iPhone X 使用自行開發的 A11 處理器,內建雙核心的「神經網路引擎(Neural Engine, NE)」,專門處理圖像辨識相關的機器學習、推論模型、演算法,也是一種針對人工智慧這種「特定應用」所開發的積體電路,不同的是它裝置在「終端」,也就是使用者的手機上,讓手機可以「自動學習」認識使用者的臉部特徵,蘋果公司也一再強調,使用者所有的臉部特徵都在手機終端完成,不會上傳到雲端處理,因此絕對不會有資料外洩的疑慮。蘋果公司這次發表的 iPhone X 讓使用者能夠真實感受終端裝置的人工智慧(On-device AI), 在可以預見的未來,終端的處理器如何與人工智慧結合形成「終端智能(edge intelligence)」, 將是愈來愈熱門的議題。
框架問題
人工智慧只能解決給定的問題,也就是問題必須在一定的「框架」內,稱為「框架問題(frame problem)」。例如:樹搜尋(tree search)是很久以前就已經在使用的演算法,在應用上有兩個限制,其中一個是只能應用在範圍有限的問題,例如:五子棋、西洋棋、象棋等,不論怎麼變化都不會超出棋盤上的方格。
符號接地問題
電腦無法把符號(文字或詞彙)與它所代表的意義相互連結(接地)起來,稱為「符號接地問題(symbol grounding problem)」。也就是電腦很難理解我們所謂的「意義」,因此無法產生「智慧」。
例如對於一個從來沒有看過斑馬的人,只要我們告訴他有一種動物的外觀很像馬,但是身上有條紋,叫做斑馬。當這個人看到真正的斑馬立刻會知道:這大概是所謂的斑馬吧!因為他理解「馬」和「條紋」這兩個符號(詞彙)的「意義」。
人類可以擴張「符號」所代表的「意義」,但是電腦使用符號時必須在一定的「框架」內,也就是使用者必須預先定義,明確的告訴電腦某個符號代表某個東西,這是人工智慧最困難的地方。
機器學習
顧名思義機器學習就是要讓機器(電腦)像人類一樣具有學習的能力,要了解機器學習,就先回頭看看人類學習的過程,人類是如何學會辨識一隻貓的?大致上可以分為「訓練(training)」與「預測(predict)」兩個步驟,到底這兩個步驟是如何進行的呢?
如何學習? 機器的學習與判斷
大腦的學習與判斷
要了解機器學習,就先回頭看看人類學習的過程,人類是如何學會辨識一隻貓的兩個步驟如下:
➤ 訓練:
小時候父母帶著我們看標註了動物名字的圖片,我們看到一隻小動物有四隻腳、尖耳朵、長鬍子等,對照圖片上的文字就知道這是貓,如果我們不小心把老虎的照片當成貓,父母會糾正我們,因此我們就自然地學會辨識貓了,這就是我們學習的過程,也可以說是父母在「訓練」我們。
➤ 預測:
等我們學會了辨識貓,下回去動物園看到一隻具有四隻腳、尖耳朵、長鬍子的小動物,我們就知道這是貓,如果我們不小心又把老虎當成貓,父母會再次糾正我們,或者我們自己反覆比較發現其實老虎和貓是不同的,即使父母沒有告訴我們,這個是我們判斷的過程,也可以說是我們在「預測」事物。
機器的訓練與預測
要讓機器(電腦)像人類一樣具有學習與判斷的能力,就要把人類大腦學習與判斷的流程轉移到機器(電腦),基本就就是運用數據進行「訓練」與「預測」,包括下列四個步驟:
➤ 獲取數據:
人類的大腦經由眼、耳、鼻、舌、皮膚收集大量的數據,才能進行分析與處理,機器學習也必須先收集大量的數據進行訓練。
➤ 分析數據:
人類的大腦分析收集到的數據找出可能的規則,例如:下雨之後某個溫度與濕度下會出現彩虹,彩虹出現在與太陽相反的方向等。
➤ 建立模型:
人類的大腦找出可能的規則後,會利用這個規則來建立「模型(model)」,例如:下雨之後某個溫度與濕度、與太陽相反的方向等,就是大腦經由學習而來的經驗,機器學習裡的「模型」有點類似我們所謂的「經驗」。
➤ 預測未來:
等學習完成了,再將新的數據輸入模型就可以預測未來,例如:以後只要下雨,溫度與濕度達到標準,就可以預測與太陽相反的方向就可能會看到彩虹。
機器學習的分類
機器學習和人類學習的過程類似,要先進行「分類(classication)」,才能分析理解並且進行判斷,最後才能採取行動,分類的過程其實就是一種「是非題(Yes or No)」,例如:這一張照片「是(Yes)」貓或「非(No)」貓。機器學習是由電腦執行程式自行學習,一邊處理大量資料,一邊自動學會分類方式,就如同人類在學習一樣,因此機器學習就是在進行資料處理,有許多不同的形式與名稱,包括:資料科學(data science)、資料探勘(data mining)、統計模式(statistical modeling)、預測分析(predictive analytics)、知識發現(knowledge discovery)、圖形辨識(pattern recognition)、自我調適系統(adaptive systems)、自我組織系統(self-organizing systems)等,其實都是機器學習的一種。
機器學習的種類
➤ 監督式學習(supervised learning):
所有資料都有標準答案,可以提供機器學習在輸出時判斷誤差使用,預測時比較精準,就好像摸擬考有提供答案,學生考後可以比對誤差,這樣聯考時成績會比較好。例如:我們任意選出 100 張照片並且「標註(label)」哪些是貓、哪些是狗,輸入電腦後讓電腦學習認識貓與狗的外觀,因為照片已經標註,電腦只要把照片內的「特徵(feature)」取出來,將來在做預測時只要尋找這個特徵(四隻腳、尖耳朵、長鬍子)就可以辨識貓了!這種方法等於是人工分類,對電腦而言最簡單,但是對人類來說最辛苦。
➤ 非監督式學習(un-supervised learning):
所有資料都沒有標準答案,無法提供機器學習輸出判斷誤差使用,機器必須自己尋找答案,預測時比較不準,就好像摸擬考沒有提供答案,學生考後無法比對誤差,這樣聯考時成績會比較差。例如:我們任意選出 100 張照片但是沒有標註,輸入電腦後讓電腦學習認識貓與狗的外觀,因為照片沒有標註,因此電腦必須自己嘗試把照片內的「特徵」取出來,同時自己進行「分類」,將來在做預測時只要尋找這個特徵(四隻腳、尖耳朵、長鬍子)就可以辨識是「哪一類動物」了!這種方法不必人工分類,對人類來說最簡單,但是對電腦來說最辛苦。
➤ 半監督式學習(semi-supervised learning):
少部分資料有標準答案,可提供機器學習輸出判斷誤差使用;大部分資料沒有標準答案,機器必須自己尋找答案,等於是結合監督式與非監督式學習的優點。例如:我們任意選出 100 張照片,其中 10 張標註哪些是貓、哪些是狗,輸入電腦後讓電腦學習認識貓與狗的外觀,等電腦只要把照片內的特徵取出來,再自己嘗試把另外 90 張照片內的特徵取出來,同時自己進行分類。這種方法只需要少量的人工分類,又可以讓預測時比較精準,是目前最常使用的一種方式。
➤ 增強式學習(reinforcement learning):
機器自己嘗試錯誤並且找出最佳答案,可以視為一種「非監督式學習」。前面介紹的三種學習方式,都必須有明確的答案,也有明確的決策,例如:這封信是不是垃圾郵件?這張照片是不是貓?如果遇到必須做出連續決策的時候,就必須一步步修正答案與決策,例如:進行圍棋遊戲時,必須依照對手的每一步棋來修正下一步要怎麼走,或是自動駕駛車,必須依照路況的變化來修正下一步要怎麼走等。
馬可夫決策過程
馬可夫決策過程(Markov Decision Process, MDP)的概念是「事件未來的情況只和現在有關,和過去無關」,主要在討論一個隨機動態系統的最佳決策過程。機器學習裡的增強式學習,每進行一步就檢查是距離目標更近或更遠,如果更接近目標則給予「正向回饋(positive feedback)」,如果更遠離目標則給予「負向回饋(negative feedback)」,這樣最後的決策就會愈來愈接近正確的答案。
很多人以為人工智慧只是應用在圍棋 AlphaGo 打敗世界棋王或是智慧機器人,似乎和我們沒有立即的關係,其實前面介紹的這些機器學習相關的資料處理演算法,早就應用在我們日常生活裡了!當瀏覽器收集了我們上線瀏覽網頁的資料,演算法就開始分析我們的行為並且預測我們會對什麼東西有興趣,於是許多相關的廣告就顯示在瀏覽器旁邊,由於瀏覽器的空間有限只能先選擇已知過去的資料分析出我們可能最有興趣的,再依照我們現在點擊的情況修正未來投放的廣告內容,其實這就是利用馬可夫決策過程的一種增強式學習,包括:Google 廣告決定投放什麼內容、Facebook 把我們最可能有興趣文章放前面等都是利用這個技術。
人工智慧的「大腦」──類神經網路
人工神經網路
人類大腦的神經網路是由「神經元(neural)」組成, 人工神經網路(articial neural network, ANN)又稱為「類神經網路」,是一種模仿生物神經網路的結構和功能所產生的數學模型,用於對函式進行評估或近似運算,是目前人工智慧最常使用的一種「模型」。
神經網路(neural network, NN)
人類大腦的神經網路是由「神經元」組成,大腦中大約有860 億個神經元,神經元是用來感知環境的變化,再將信息傳遞給其他的神經元,基本構造包括:細胞體(內含細胞核)、樹突(dendrites)、軸突(axon)組成,如圖三 (a) 所示:
➤ 突觸(synapse):
神經元與神經元、肌肉細胞、及腺體細胞之間通信的特異性接頭(junction),用來傳遞生物電流或化學物質(多巴胺、乙醯膽鹼)。
➤ 接收區(receptive zone):
為樹突到胞體的部份,用來接收生物電流或化學物質,如果接收的來源越多,對胞體電位的影響越大。
➤ 觸發區(trigger zone):
位於軸突和細胞體交接處的「軸丘(axon hillock)」,用來決定是否產生神經衝動的起始點。
➤ 傳導區(conducting zone):
為軸突的部份,用來傳導神經衝動。
➤ 輸出區(output zone):
神經衝動的目的是讓神經末梢,也就是突觸傳遞生物電流或化學物質,才能影響下一個神經元、肌肉細胞、腺體細胞。
科學家模仿人類大腦的神經網路,提出了「赫布理論(Hebbian theory)」,用來解釋學習過程中大腦神經元變化的神經科學理論,突觸上一個神經元向突觸下一個神經元持續重複的刺激,可以導致突觸傳遞效能的增加,也就是人工神經網路上的「權重(weight)」。
我們把人類大腦複雜的「神經元」簡化成一個圓圈和一個箭號,如圖三 (b) 所示,圓圈內的數字代表這個神經元的神經衝動強度,箭號旁的數字代表這個神經元突觸傳遞效能,也就是「權重」,則大腦內複雜的神經網路就可以簡化成人工神經網路,如圖四所示,一層層的連結起來,以手寫辨識數字為例,「輸入層」就是我們手寫的數字,「輸出層」就是辨識的結果數字 0~9。
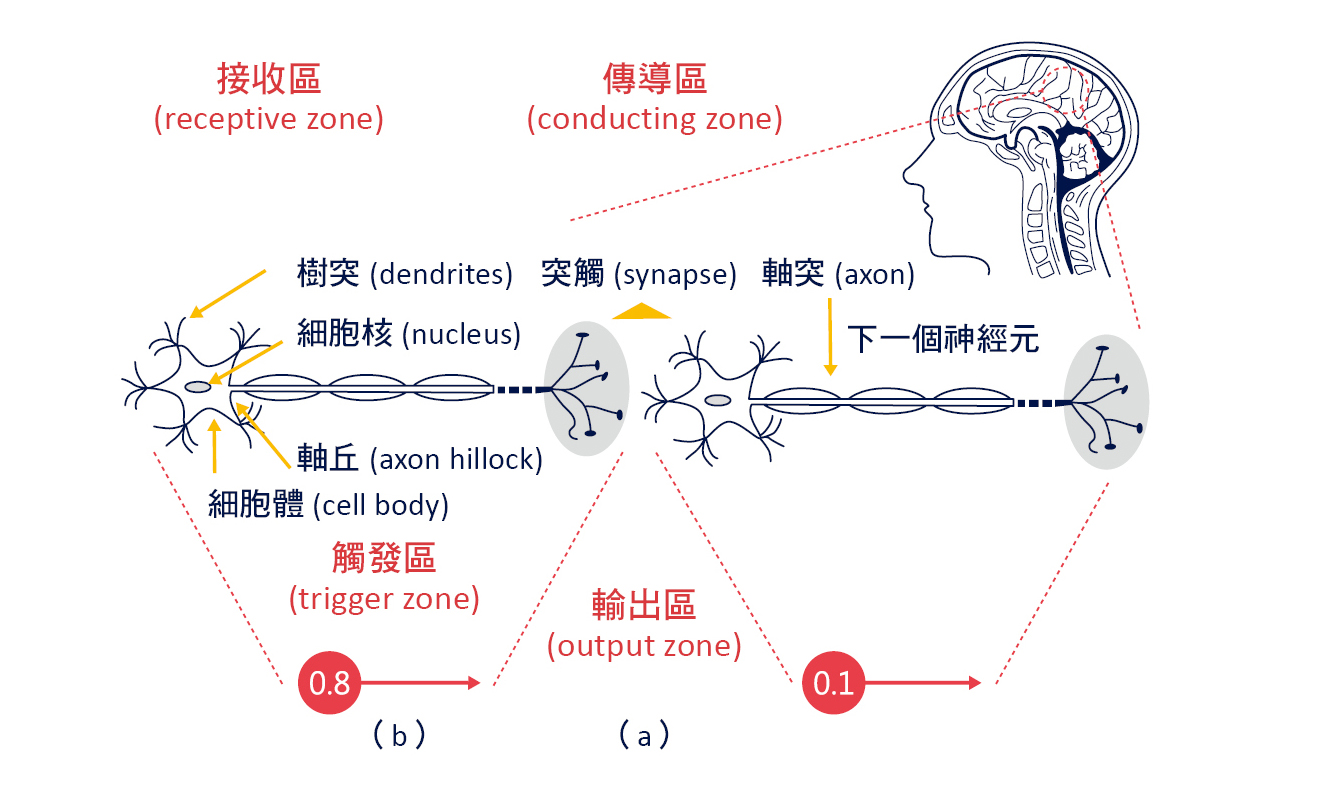
▲圖三:人類大腦的神經網路(NN)示意圖。
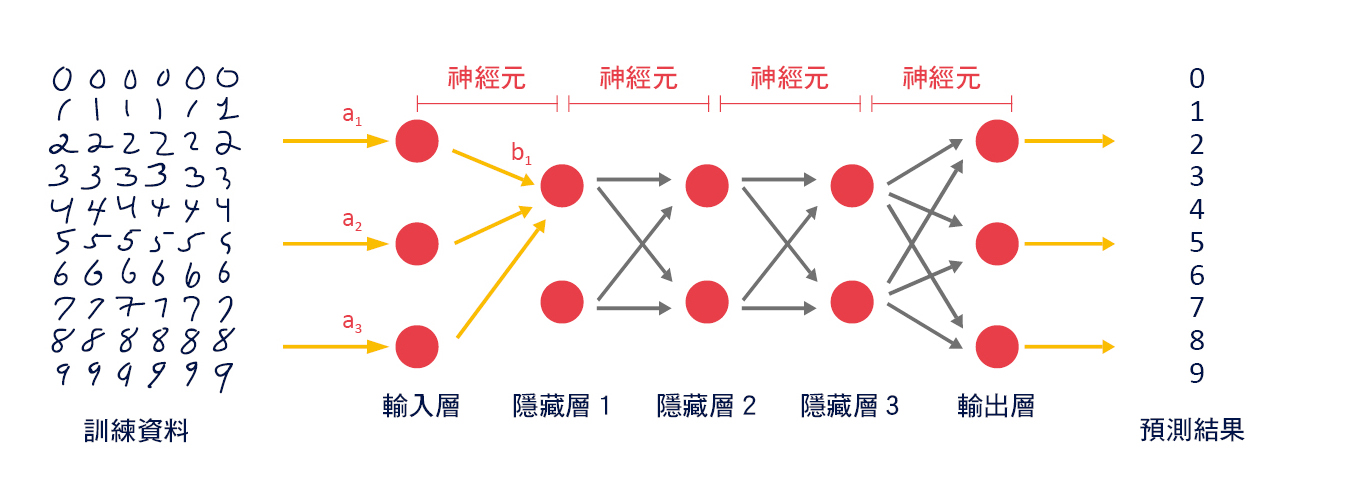
▲圖四:人工神經網路(ANN)示意圖。
單層感知器(single layer perceptron, SLP)
1958 年羅森布拉特(Frank Rosenblatt)發明「感知器(perceptron)」, 經由赫布理論最小化單層網路的權重,是第一個以演算法精確定義的神經網絡,也是第一個具有自我學習能力的數學模型,為後續人工神經網路模型的始祖,神經網路模型的運算原理很簡單,這一個神經元由前一個神經元接收到電氣訊號達到某一個「門檻值(threshold point)」就會產生神經衝動,同時把電氣訊號傳送給下一個神經元,運算步驟如下:
➤ 乘加運算(sun of product, SOP):
下一個神經元(b1)接收到的訊號強度是由這一層神經元(a1/a2/a3)進行加權(w1/w2/w3)之後的總和(Sum),如圖五 (上) 所示。
➤ 激勵函數(activation function):
感知器使用激勵函數的目的是引入非線性,如圖五 (下) 所示,常見的激勵函數有邏輯函數(sigmoid function)、雙曲函數(tanh)、線性整流函數(rectified linear unit, ReLU)等,在人工神經網路中如果不使用激勵函數,那麼都是以上一層神經元輸入的線性組合作為這一個神經元的輸出,輸出和輸入脫離不了線性關係,則深度神經網路便失去意義。
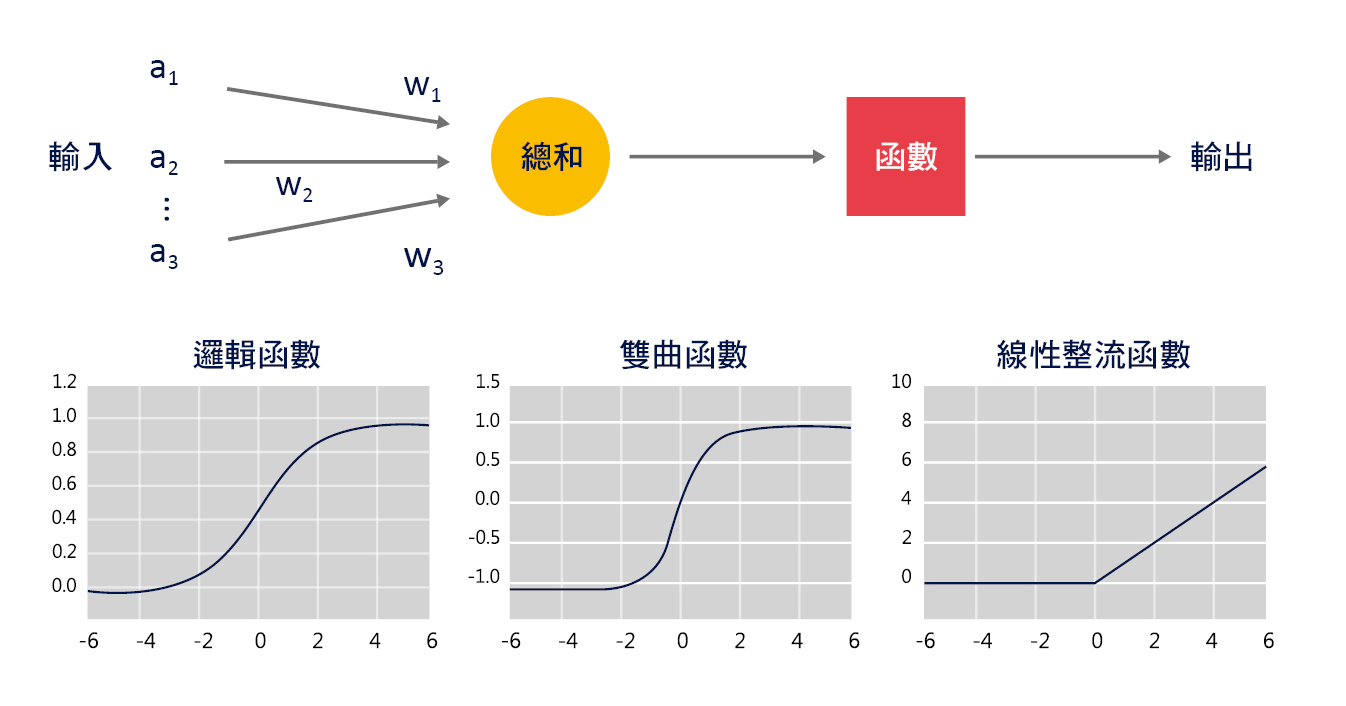
▲圖五:單層感知器(SLP)與激勵函數示意圖。
神經網路模型
人類大腦的神經元會因為反覆學習而使得突觸間傳遞作用加強,就好像這裡的人工神經網路權重變大,因此這種分類法是參考人類大腦神經網路的原理。神經網路模型(neural network model)的運算方式如圖六 (a) 所示,假設這一層神經元(a1/a2/a3)連結到下一個神經元(b1),分別為權重(w1/w2/w3),則下一個神經元(b1)的神經衝動強度為:b1=w1×a1+w2×a2+w3×a3=0.5×0.8+2.5×0.2 +(−2.9)×1.0=−2.0
如圖六 (b) 所示,再將 −2 經由「邏輯函數」轉換後得到輸出值 0.1,如圖六 (c) 所示。
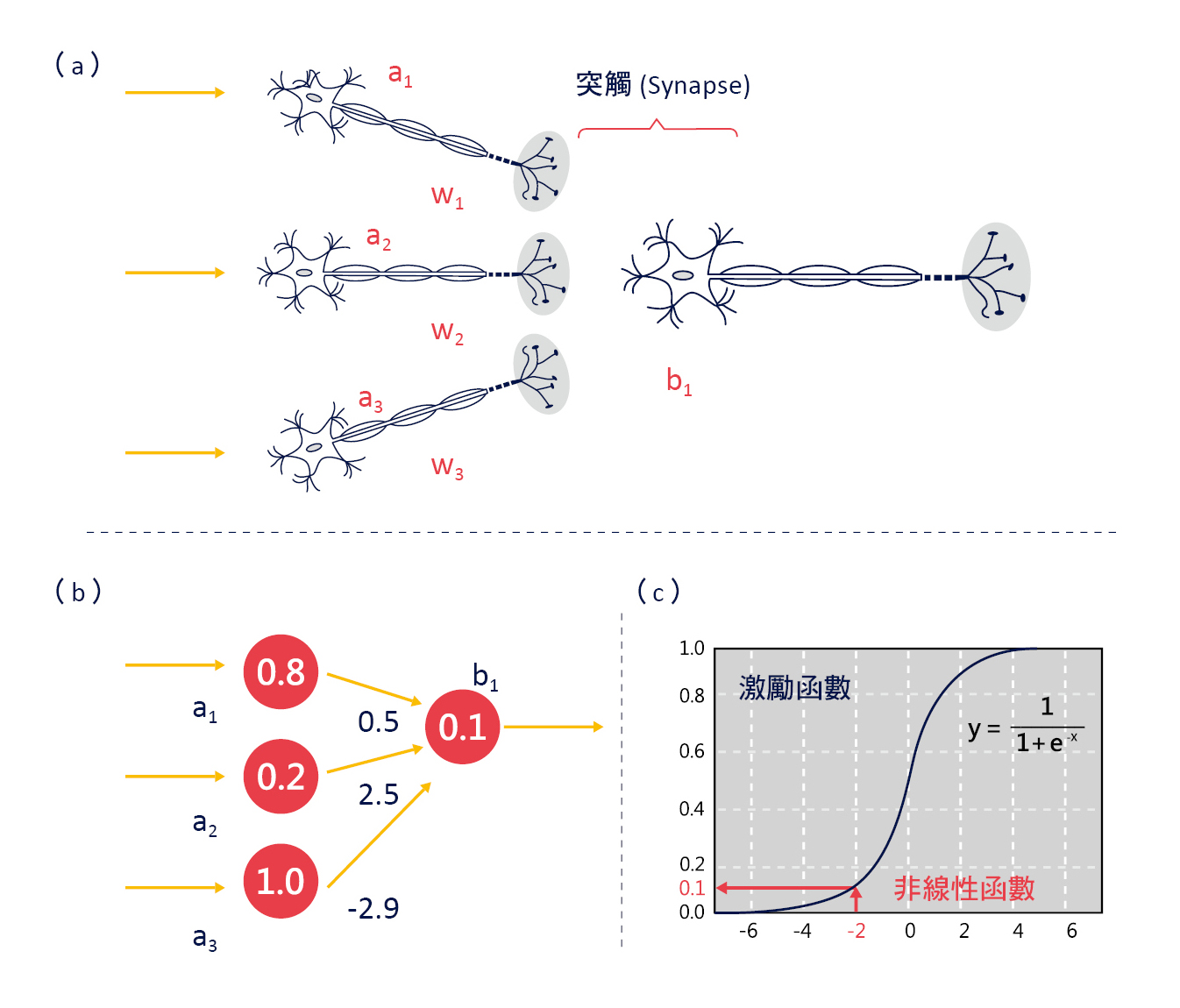
▲圖六:神經網路模型的運算方式。
經由人工神經網路 訓練電腦進行手寫辨識
在圖形辨識領域的科學家們必須共同使用的一套標準圖形資料庫,才能確定是開發出更好的演算法,而不是運氣好恰好資料比較好解讀,因此許多科學家使用「MNIST 資料庫(Modified National Institute of Standards and Technology)」,以手寫辨識為例,在 MNIST 資料庫中的每個數字都是 28×28=784 畫素(pixel)的灰階圖片,每一個畫素可以轉換成一個 0~255 的數字,其中 0 代表黑色,1 代表有一點亮的灰色,2 代表更亮的灰色,依此類推,255 代表白色,如圖七所示。總共有七萬張圖片,每一個手寫數字圖片都有標準答案對應到正確的數字,因此是屬於「監督式學習(supervised learning)」。
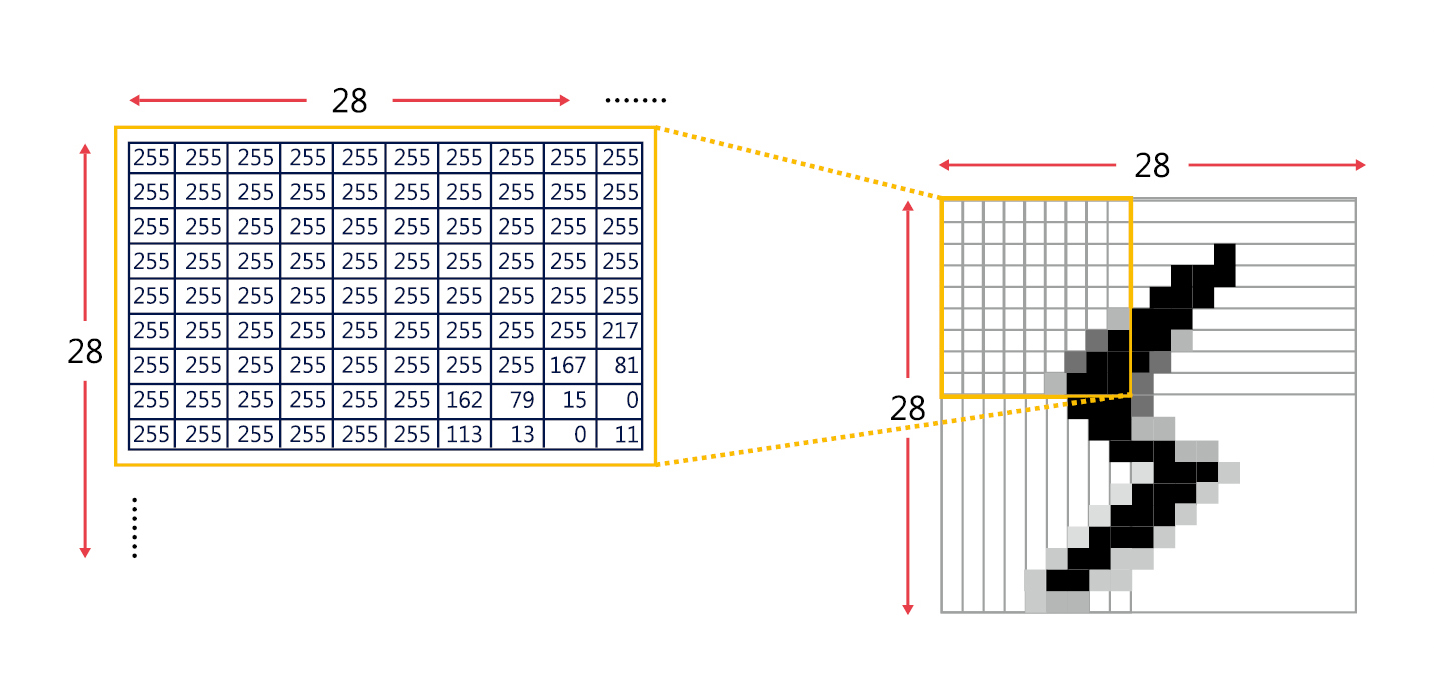
▲圖七:MNIST 資料庫中的每個數字都是 28×28=784 畫素的灰階圖片。
由於每個數字都是 28×28=784 畫素,因此輸入層有 784 個維度,假設我們設定隱藏層有 100 個維度,輸出層只有數字 0~9 總共 10 個維度,如圖八所示。
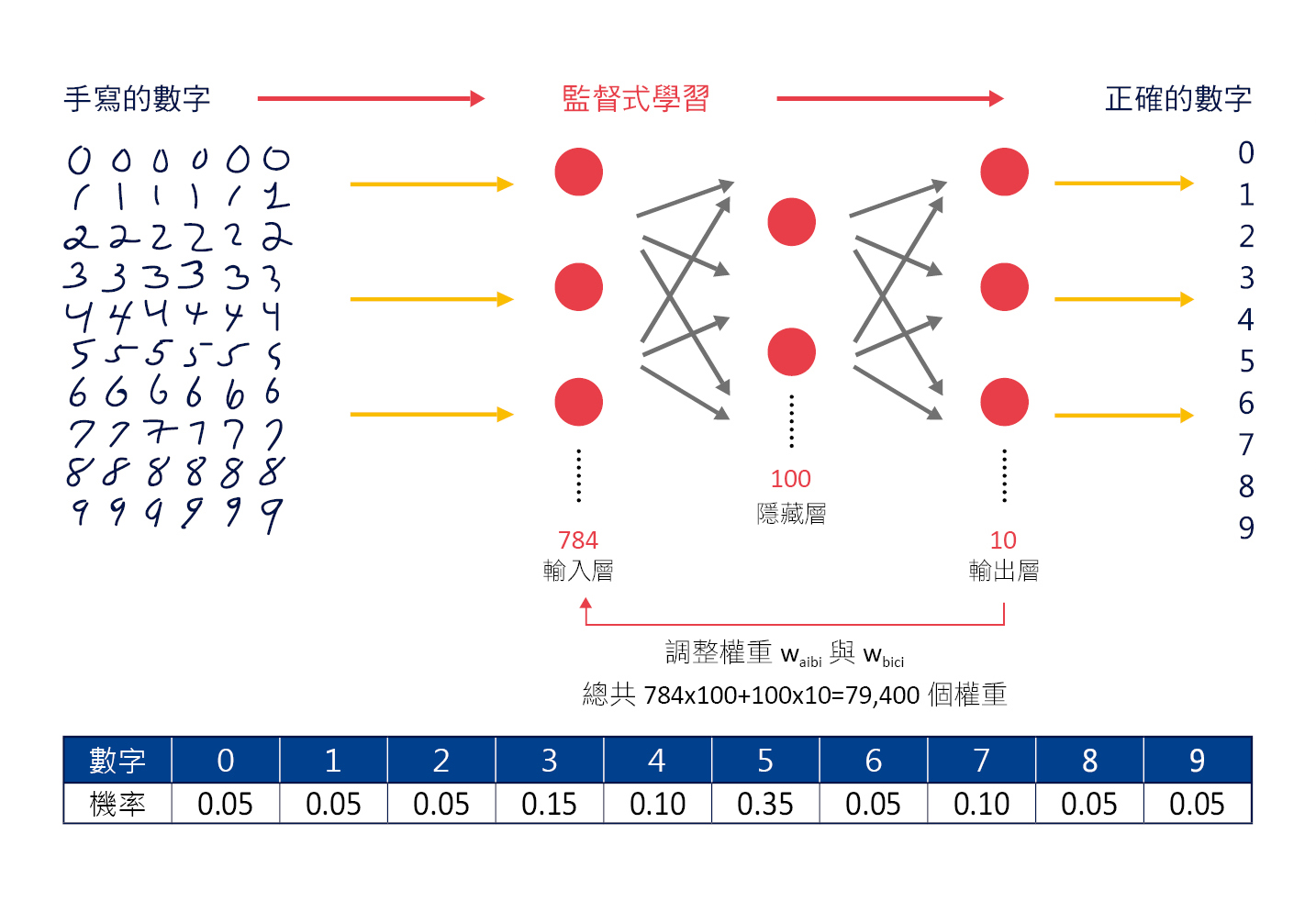
▲圖八:手寫辨識的人工神經網路運算示意圖。
➤ 輸入層(input layer):
每一個畫素的數字就是輸入層的 1 個維度,總共 784 畫素,所以輸入層總共 784 個維度(a1~a784)的輸入。
➤ 隱藏層(hidden layer):
假設我們設定隱藏層有 100 個維度(b1~b100)。
➤ 輸出層(output layer):
只有數字 0~9 總共 10 個維度(c1~c10)。除了每一層的維度,我們還要注意每一層之間的「權重」,在這個例子裡總共有 784×100+100×10=79400 個權重,我們來計算一下隱藏層的 100 個維度(b1~b100):b1=w(a1b1)×a1+w(a2b1)×a2+w(a3b1)×a3+⋯⋯+w(a784b1)×a784b2=w(a1b2)×a1+w(a2b2)×a2+w(a3b2)×a3+……+w(a784b2)×a784 代此類推 b100=w(a1b100)×a1+w(a2b100)×a2+w(a3b100)×a3+……+w(a784b100)×a784
再計算一下輸出層的 10 個維度(c1~c10):c1=w(b1c1)×b1+w(b2c1)×b2+w(b3c1)×b3+……+w(b100c1)×b100c2=w(b1c2)×b1+w(b2c2)×b2+w(b3c2)×b3+……+w(b100c2)×b100 代此類推 c10=w(b1c10)×b1+w(b2c10)×b2+w(b3c10)×b3+……+w(b100c10)×b100
誤差反向傳播(error back propagation, EBP)
人類的神經元會因為反覆學習而使得突觸間傳遞作用加強,就好像這裡的人工神經網路權重變大,因此這種分類法是參考人類大腦神經網路的原理。經由微分計算每一個權重變大或變小時,輸出與輸入的誤差會變小,接著調整所有權重,也就是所有的 w(aibi)與 w(bici),使輸出與輸入的誤差變小。這個觀念類似主管經由員工提供的資訊進行判斷,正確的資訊是由下(員工)往上(主管)提供(反向傳播),而修正時由上(主管)向下(員工),慢慢就會判斷正確。
➤ 神經網路的訓練與預測
我相信大家看到這裡頭就開始昏了,事情還沒結束,神經網路的學習與預測流程比前面講的還要複雜:
➤ 訓練階段:
輸入大量已知答案的資料進行訓練,當結果出現錯誤就調整 79400 個權重,反覆進行直到輸出的結果接近標準答案,可能需要幾秒也可以需要幾天。例如:輸入七萬張手寫數字圖片都有標準答案對應到正確的數字,每當任何一張圖片輸出結果錯誤就調整所有 79400 個權重,也就是所有的 w(aibi)與 w(bici)。
➤ 預測階段:
輸入不同於訓練階段的新資料,經由已經調整好的 79400 個權重計算後輸出結果,只需要一瞬間就可以完成,精確度有賴於訓練時得到的權重。
由上面的例子可以看出,神經網路的訓練與預測和人類的學習與判斷過程相似,我們通常都是花很長的時間學習(訓練),但是學會之後進行判斷(預測)只需要一瞬間就可以了。
機器學習的模型
資料科學是一種收集資料、了解資料、分析資枓、預測資料的科學,資料裡不同變數之間存在數學上或機率上的規則稱為「模型」,可以應用在許多地方,例如:圍棋比賽可以運用某種模型分析出過的牌、出現的牌來評估每個玩家的勝率,模型必須基於圍棋規則、機率理論、基本假設等來建立。
機器學習就是經由資料分析建立模型,並且使用這個模型來預測結果。有人把這種技術稱為資料探勘或「預測建模(predictive modeling)」,例如:預測某封電子郵件是否為垃圾郵件、預測某筆線上交易是否為詐欺行為等。
為了建立模型必須選擇相關的「特徵值(feature value)」,我們稱為「特徵選擇(feature selection)」,特徵值是機器學習在輸入時所使用的「變數(valuable)」,它的數值可以定量呈現目標的特徵,隨著挑選特徵值的不同會讓精確度產生很大的影響。例如:手寫辨識必須調整手寫文字的中心與大小,並不是把手寫文字切割成許多畫素再輸入神經網路就可以得到精確度。
深度學習
深度學習(深度神經網路)是讓電腦可以自行分析資料找出「特徵值」,而不是由人類來決定特徵值,就好像電腦可以有「深度」的「學習」一樣。深度學習不但使用多層神經網路,同時使用「自動編碼器(autoencoder)」來進行「非監督式學習(un-supervised learning)」。
人工智慧的困難
機器學習有許多方法可以進行資料分類,近年來最流行也被證明最成功的方法就是「人工神經網路」,經由前面的介紹,我們知道人工神經網路是如何調整權重,使輸出與輸入的誤差變小,但是即使如此,這和我們想要的「人工智慧」,也就是人工創造出來可以思考的電腦還有很大的差距,直到今日人工智慧無法實現的主要原因包括:
➤ 專家系統:
輸入知識讓電腦變聰明,但是沒有自行學習的機制,必須先請專家提供所有知識,而且知識無窮無盡永遠也寫不完,知識數量太多彼此產生矛盾,無法處理不明確的答案。
➤ 框架問題:
只能解決給定的問題,也就是問題必須在一定的「框架」內,對於不同的任務無法事先決定該使用什麼知識。
➤ 符號接地問題:
無法把符號(文字或詞彙)與它所代表的意義相互連結起來,也就是電腦很難理解我們所謂的「意義」,因此無法產生「智慧」。
➤ 機器學習:
利用人工神經網路與誤差反向傳播來訓練電腦學習,但是必須由人類決定特徵值,電腦才能依照這個特徵值來訓練。
符號與意義
如果電腦可以自行分析資料找出特徵值,那就更接近我們想要的人工智慧,也就是人工創造出來可以思考的電腦。這個時候電腦能夠自己分析資料理解「有斑紋的馬」這個特徵,只要人類告訴電腦這個特徵所使用的符號叫「斑馬」,就把符號與它所代表的意義相互連結(接地)了!
符號「貓」或「Cat」,意義是指尖耳朵、尖眼睛、長鬍子很可愛的一種動物,這些就是「特徵值」。人工智慧面臨許多問題就是因為電腦無法自行理解符號的「意義」,而最近發展的「深度學習」已經可以讓電腦自行分析資料找出「特徵值」。
Google 貓臉辨識計畫
Google 公司 2012 年做了一個實驗,由 YouTube 的影片中取出 1000 萬張圖片,使用具有 100 億個神經元的深度學習神經網路,由 1000 台電腦(16000 個處理器),運算三天才完成。
➤ 將 1000 萬張圖片輸入深度學習神經網路,經由數層神經網路使電腦自行學習找出「特徵值」而能夠辨識「對角斜線」,如圖九 (a) 所示。
➤ 再經由數層神經網路使電腦能夠辨識「人臉」,如圖九 (b) 所示,以及「貓臉」,如圖九 (c) 所示,形成抽象度愈高的「特徵值」,最後經由特徵值理解這個東西的「意義」。
➤ 此時只要我們告訴電腦具有圖九 (b) 這個特徵值的東西稱為「人(符號)」;具有圖九 (c) 這個特徵值的東西稱為「貓(符號)」,電腦就能夠將符號與意義產生連結(接地)了!
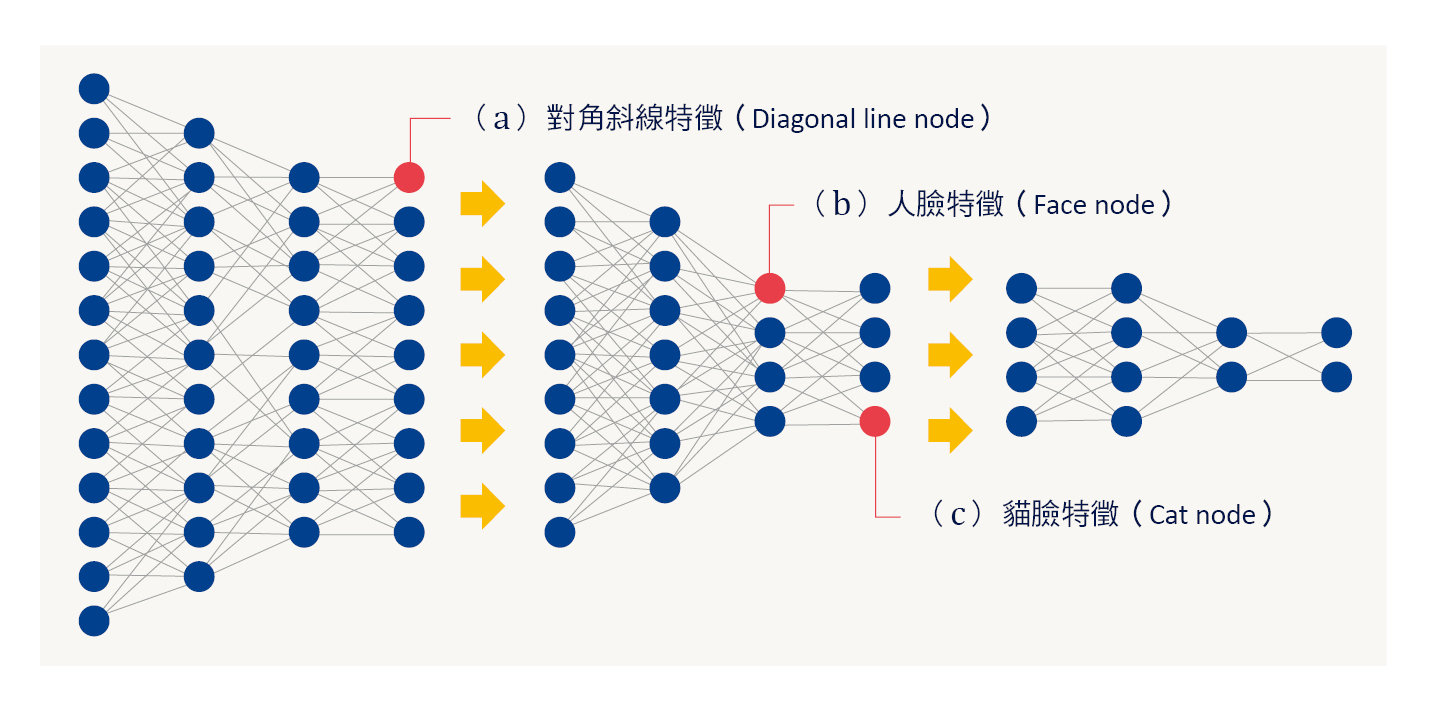
▲圖九:Google 貓臉辨識計畫深度學習神經網路示意圖。
未來只要我們輸入其他照片,電腦就能夠自動判斷這個是人,那個是貓,這個學習的過程其實和人類學習過程是類似的。
人工智慧的未來
講到這裡,大家應該都有感覺,目前我們聽到業界在討論的人工智慧,只是一種用簡單的公式模擬人類大腦神經元進行重複大量計算的結果,也可以說是一種分析數據的電腦程式,距離科幻電影裡真正會思考的電腦還有很大的差距,人工智慧的演算法應用在數據分析的確帶許多突破,但是有些廠商刻意誇大它的效果來達到募資的效果,在投資分析時不得不慎。
延伸閱讀
松尾豐,江裕真譯,《了解人工智慧的第一本書》,經濟新潮社,2016 年。
⇠上一篇:不只是一項科技人工智慧對未來的反思



