

















大數據與現代生活的連結
鄭江宇∕國立中央大學資訊管理博士,現任東吳大學巨量資料管理學院助理教授,專長為大數據與人工智慧研發。
在談論數據之前,首先必須理解數據(data)的定義及其來源。一般來說,數據又可稱作資料,是指未經過處理的原始紀錄,人類即為重要的資料生產者,時時刻刻從生活中產出新的資料,而這些資料會經過一連串的演進,最終成為富有價值的智慧(圖一)。

▲圖一:資料轉為資訊、知識與智慧流程示意圖。
舉一個簡單的例子,假設讀者早上到早餐店點了一份 30 元的原味蛋餅搭配一杯 30 元的美式咖啡,此紀錄就是一筆未經處理的飲食資料。但當想要進一步了解自己在早餐上的花費,此時就需要將這筆資料做進一步處理,計算出自己在早餐的總花費為 60 元,而此經過處理後的資料即稱為「資訊(information)」。
有了總花費資訊後,自己開始有所認知,原來今天在早餐上的花費吃得如此節省,此基於過去經歷所做出的比較及歸納,則是資訊轉化成為「知識(knowledge)」的過程。於是可以開始思考,既然早餐吃得那麼簡單,那麼下課後的晚餐應該要犒賞一下自己,吃得更豐盛、更健康,於是決定打算晚上去吃火鍋,這項經由判斷及分析所做出的決策即是「智慧(wisdom)」。
上述的例子只不過是記錄一個人在早餐上的飲食資料,但若要記錄全臺灣 2300 多萬人的飲食資料呢?對此,大數據(Big Data)便躍上檯面,不過各位讀者可千萬別誤會,難道是因為資料量瞬間放大 2300 萬倍才被稱作是大數據嗎?
其實不然,資料量龐大只不過是大數據的必要條件之一,重點在如何從大量資料或數據中挖掘出過去未曾被發現的知識,進而從中得到智慧成為人們下決策的依據。早在 1959 年,與大數據類似的名詞與概念就已被學者們提出,但受限於當時硬體設備不足,例如資料儲存空間不足或資料處理速度不夠快等,使得大數據分析在當時並未成功地被實現。直至 2012 年,受惠於連網速度與資料儲存量的提升,過去那些無法被收集與利用的寶貴資料,現今已經可以順利地被捕捉,也正式宣告大數據時代來臨。
大數據的 4V 特性
資料必須具備哪些特性才有資格被稱作是大數據呢?關於大數據的特性眾說紛紜,其中又以拜雅(Mark Beyer)以及蘭尼(Douglas Laney)論文中所提出的 4V 觀念最為被大眾接受(圖二),包括資料量龐大(volume)、資料型態多樣(variety)、資料處理速度快(velocity)及資料具真實性(veracity)。
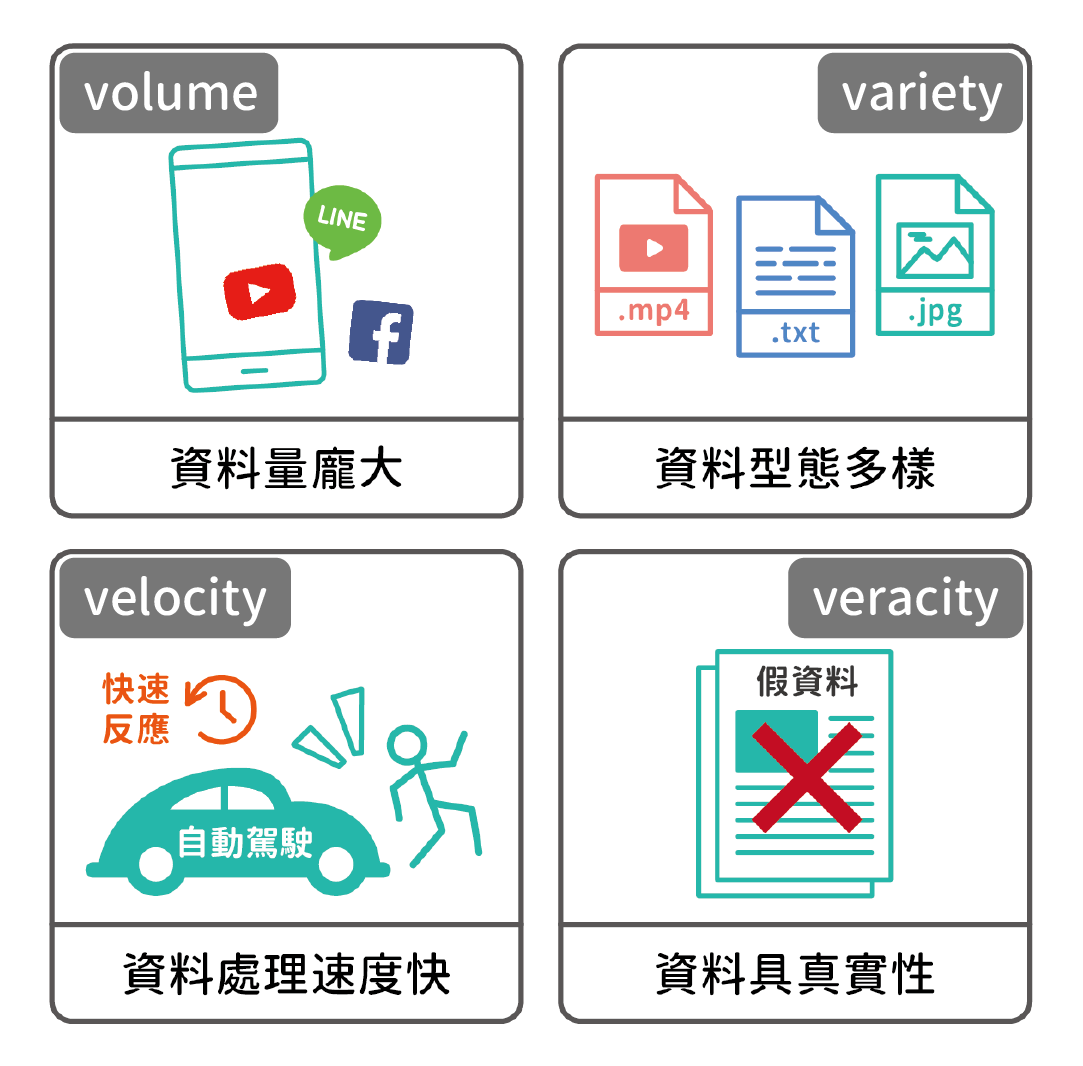
▲圖二:需包含夠大的資料量、各種不同型態的資料、快速的處理及杜絕各種假資料。
➤資料量龐大
試想人手一支的手機在一天內能夠累積多少數據呢?舉凡 LINE 的聊天數據、YouTube 影片的觀看次數、網路購物上的選擇路徑及玩遊戲的操作數據等,實在難以估算。不過資料量到底該多大,容量要達到 TB 還是 PB 單位才夠資格呢?其實目前並沒有一個確切的參考標準,重點在於是否能夠從數據中挖掘出有價值的發現並幫助人們下達正確決策。
➤資料型態多元
在過去沒有電腦的時代,只能依靠紙筆以文字型態記錄資料。而現今有了相機、攝影機與錄音機等硬體設備,資料能夠以圖像、影像及聲音的型態進行儲存,代表大數據時代必須處理多元資料型態的事實。
➤資料處理速度快
為提升行車安全及品質,無人駕駛汽車嵌入多種感測裝置,分分秒秒對周邊環境進行資料收集,但是讀者能夠想像當電腦無法針對路況即時反應所造成的嚴重後果嗎?因此資料處理快速是大數據的必要條件之一,也是硬體設備升級的成果。
➤資料具真實性
假新聞會導致閱聽大眾的錯誤認知,甚至影響社會正常運作。同理,錯誤資料來源也會造成分析結果誤差,甚至影響人們下達的重大決策,因此確保資料來源的可信程度也是大數據的重點之一。
大數據的運作機制
大數據的運作大致可分為資料收集、資料儲存、資料處理及資料分析等四大環節(圖三),面對需即時處理及數量龐大的數據,資料科學家也有相對應的解決方案與技術。
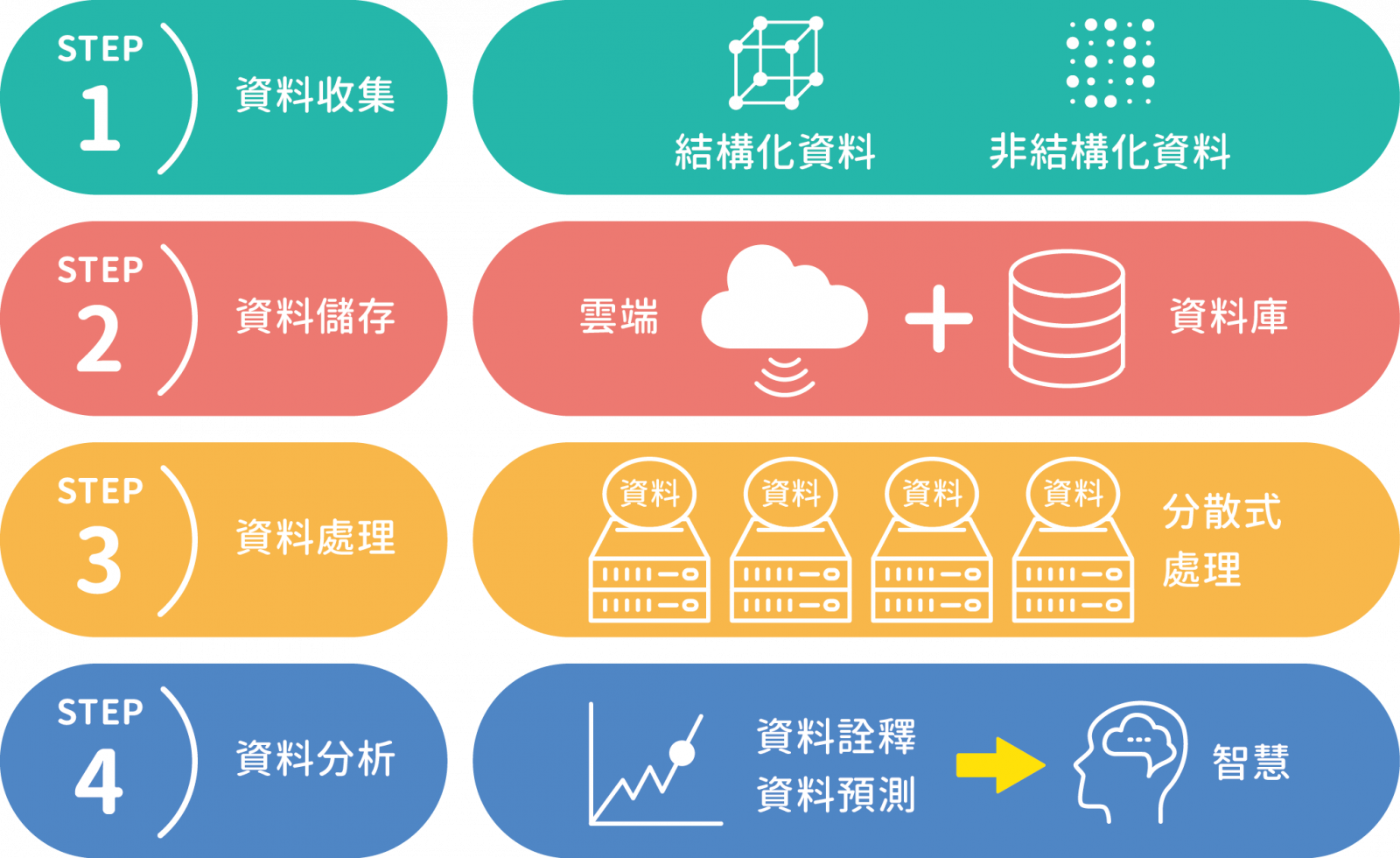
▲圖三:大數據的運作機制,從資料收集、儲存、處理到分析的過程圖。
首先在資料收集上,受惠於物聯網(Internet of Things, IoT)技術,資料得以被有效地採集與傳送,這些資料可略分為結構化資料(structured data)與非結構化資料(unstructured data)。前者是已經整理好的資料,具備固定的格式與順序,可以直接被放進資料庫正確的欄位中儲存;後者則是指亂成一團的資料,例如一段影片或者一張圖片等,必須經過處理才得以再利用。但很不幸地,天底下沒有白吃的午餐,在大數據時代中多數資料皆屬於非結構化資料,因此資料處理目的就是要整理這些雜亂無章的資料。
不過,在此之前還有一個重要的問題,那就是收集下來的龐大資料該儲存在哪裡呢?答案是雲端,也就是透過網際網路向他人租用空間來進行資料儲存。至於存放資料的載體,結構化資料一般可透過結構化查詢語言(Structured Query Language, SQL)資料庫進行儲存,但面對大數據資料龐大且多為非結構化資料等特性,使用非關聯型(Not Only SQL, NoSQL)資料庫來儲存資料是現階段較為主流的方式。
完成資料儲存之後,便可從資料庫隨時取用所需的資料,並可以開始進行資料處理,在此分散式運算(distributed computing)是大數據領域相當重要的概念,就好比小組分工的概念,共同協作總比單打獨鬥的效率高,分散式運算可以將一筆大資料拆散成為多筆小資料,分別於多台電腦上進行運算最後再進行整合。此做法是為了增加資料處理效率,以印證大數據的資料快速處理特性。最後是資料分析,也就是運用各種不同的分析方法搭配領域知識(domain knowledge)試圖從資料中挖掘出有價值的事物,例如資料詮釋、資料預測等。
大數據的應用實例——讓測量變得更精準
➤精準農業
假設自己是一位農夫,是否知道該在什麼時間、地點種下何種農作物最合適?此問題可能只剩有經驗的老農才回答得出來吧!面臨農村人口老化、全球氣候異常及人口遽增等社會問題,該如何延續農業以防止後代子孫有餓肚子的風險呢?答案就是「數據」。
當代有不少科技業者提出解決方案,試圖透過大數據分析來實現精準農業。除了要收集基本的農地數據(土壤濕度、酸鹼度等)、氣候數據(空氣濕度、溫度等),還要將老農過去的栽種經驗數據化,以便進一步分析作物的生長曲線,精準地掌握作物的生長。更重要的是,即便是缺乏務農經驗的年輕人,也能仰賴大數據的智慧決策能力來達到適地適種的成果。
➤精準行銷
讀者相信電影裡的男主角人選是透過大數據挑選出來的嗎?美國影音串流平台 Netflix 為了契合收視偏好,於是對觀眾進行資料捕捉及分析,如基本資料、觀看習慣等,試圖從資料線索內釐清觀眾心中渴望的主角特徵,並以此作為依據去尋找合適的主角人選,例如影集《紙牌屋》(House of Cards)。不僅如此,Netflix 還能夠為觀眾提供客制化內容,在合適的時間點預測觀眾喜歡觀看什麼類型的電影並進行推播,即所謂的精準行銷。
精準行銷概念不只應用於影音串流平台,任何需要藉由與訪客互動來增加黏著度的平台,例如購物網站、社交網站等,亦持續透過數據捕捉來優化個人化推薦演算法,最終目標是建立最好的使用者體驗。
➤精準醫療
病患對醫生的信賴程度有多高呢?根據統計,此數值竟然從 1960 年的 75% 急劇下降至現今的 31%,主要原因是病患與醫生之間的資訊不對稱,造成許多醫生用藥錯誤的案例。
舉例來說,病患或許不知道自己屬於過敏體質,造成醫生開立可能會引發過敏反應的處方箋,進而導致病患的病情雪上加霜。很慶幸地,該情形未來也許會有所改善。醫療專家與資料科學家們合作著手建立基因資料庫,裡頭收錄每個人獨有的基因資料及過去病史紀錄。因此,當病患下次再走進醫院看病時,醫生只要在電腦中輸入基本資料,不管是與身體狀況相關的先天或後天症狀,醫生皆能夠全盤掌握並且對症下藥,這就是仰賴數據實行精準醫療的最佳典範。
大數據就在你我身邊
透過以上介紹,相信讀者對於大數據已經有了初步的概念,然而相關案例肯定是不勝枚舉,讀者不妨在自己的日常生活中多加觀察,或許就能夠發現原來大數據是如此顯而易見,深植於你我的生活當中。
⇠上一篇:實現未來科技生活的樞紐 大數據
Google、縱橫字謎與大數據:下一篇⇢



