



















淺談AlphaGo人工智慧系統
顏士淨∕東華大學資訊工程系教授,從事人工智慧,機器學習,電腦對局等研究,圍棋棋力為業餘六段。

2016 年谷歌 DeepMind 團隊的 AlphaGo 擊敗南韓九段圍棋棋王李世乭,震撼全世界,可說是人工智慧的重要里程碑。AlphaGo 主要是以人工智慧深度學習的技術開發,並以強化式學習的方式提高棋力。DeepMind 在 2014 年開始網羅機器學習與電腦圍棋菁英,包括席維爾(David Silver)、黃士傑(Aja Huang)與麥迪遜(Chris J. Maddison)等專家學者,加上充沛的計算資源與大量的資訊人才,不但影響圍棋的發展,也讓很多人開始思考人工智慧對人類未來的影響。
AlphaGo 能擊敗人類,主要是模仿人類棋士的空間比對與思考,其採用三種先進的機器學習技術:深度學習(Deep Learning, DL)、強化式學習(Reinforcement Learning, RL)及深度強化式學習(Deep Reinforcement Learning, DRL)。以下將分別敘述這三種機器學習技術。
越複雜越好——深度學習
AlphaGo 所使用的深度學習技術是一種類神經網路(Neural Network)技術,早在二十世紀中期,就有許多學者提出類神經網路的概念,而 1980 年開始,類神經網路開始實際應用在解決現實世界問題。一般的類神經網路可分為輸入層、輸出層與隱藏層,如圖一,輸入層為圖片,輸出層為圖片種類判斷,其餘則為隱藏層。而所謂深度學習網路,其中的深度就是指隱藏層的個數,增加深度可使網路有能力處理更複雜的問題。例如相對複雜的圍棋布局,AlphaGo 的深度學習網路深度設定為 13 層。而深度學習類神經網路原本用於圖形辨識問題,圖一中的深度學習網路便是用於辨識圖形,並予以分類。2011 年起,因為可以充分利用 GPU 繪圖顯示晶片的大量平行化的運算特性,大幅提高效能至實用階段。
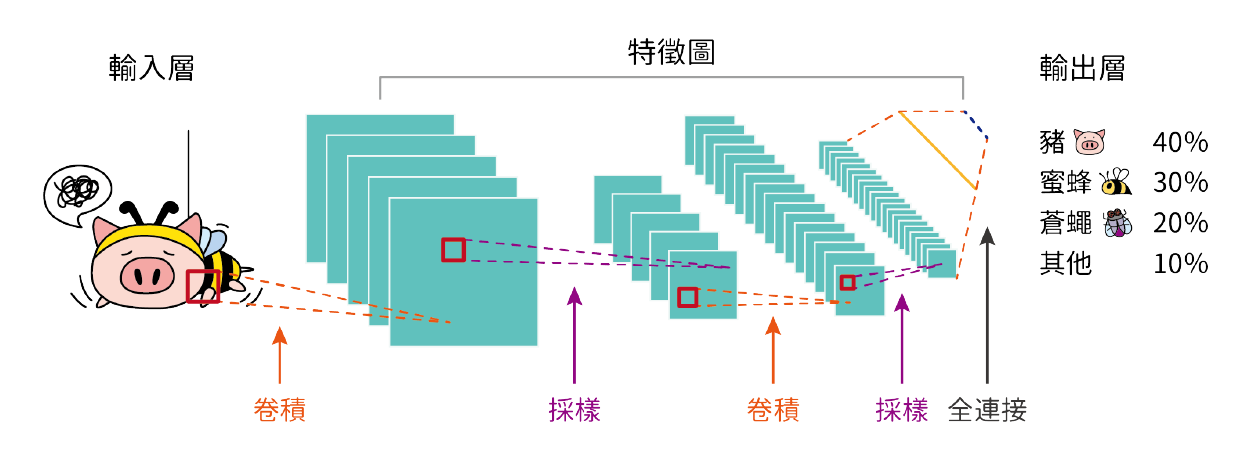
▲圖一:深度學習技術,輸入層為圖片,輸出層為圖片的判別,其餘則為隱藏層。能用於辨識圖形,並進行分類。
圍棋方面,人工智慧學界從 2008 年就有將深度卷積式類神經網路(Deep Convolutional Neural Network, DCNN)運用在圍棋的研究。而電腦圍棋界也有許多人將 DCNN 直接應用在圍棋程式裡面,趨勢科技創始人張明正曾經在 2015 年,邀請圍棋棋士王銘琬、趨勢科技的工程師與東華大學共同成立 GoTrend 團隊,同時也研究 DCNN 在圍棋的應用,在 2015 年日本 UEC 電腦圍棋比賽中獲得不錯的表現。在 2016 年日本 UEC 比賽中,前八名有 7 隊都是以深度學習技術開發。AlphaGo 團隊也採用深度學習進行辨識棋型,並預測高段棋士的著手。
蒙地卡羅樹搜尋──強化式學習
在強化式學習部分,AlphaGo 採用一種稱為蒙地卡羅樹搜尋演算法(Monte-Carlo Tree Search, MCTS),此方法近 10 年來成功地用於圍棋及許多遊戲,甚至一些數學最佳化的應用問題,如排程等。其中,樹搜尋(Tree Search)的技術使用在圍棋上,其主要的概念為:每個節點代表一個盤面,此節點的分支代表此盤面下的合法,每個分支連結到的子節點,就是原盤面加上分支代表的著手後,所產生的新節點盤面。一般而言,目前盤面為根節點,根節點的分支代表目前盤面下的合法著手,根節點的子節點代表根節點的盤面加上分支代表的著手後所形成的下一個盤面。如圖二,A 節點代表著手為黑棋 A 點的盤面,也就是根節點,B、C、D 點分別代表下在 B、C、D 點之後的盤面。
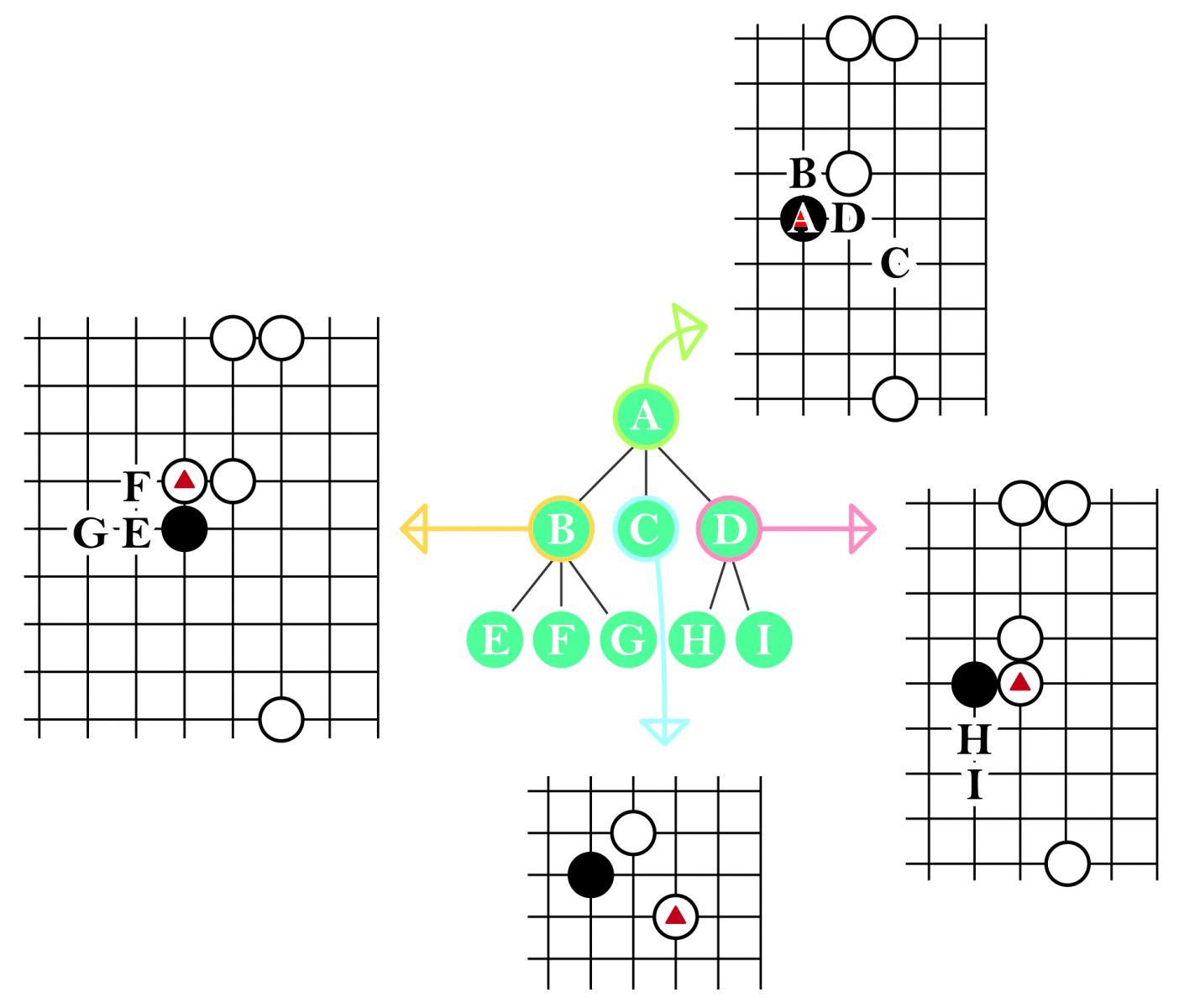
▲圖二:樹搜尋使用在圍棋,圖上的 A 節點代表黑棋 A 點盤面,B、C、D 點分別為後續的盤面。
蒙地卡羅樹搜尋的步驟如表一:

以上四個步驟不斷重複,直到指定的時間或次數用盡為止(圖三)。此時所得到的搜尋樹,其根節點之下,拜訪次數最多的子點,即為最佳著手。蒙地卡羅樹搜尋有三項優點:可停止於任意時間,時間控管方便、在處理難以預料的事物時較強健、是非對稱性展開,可以展開較深的搜尋。
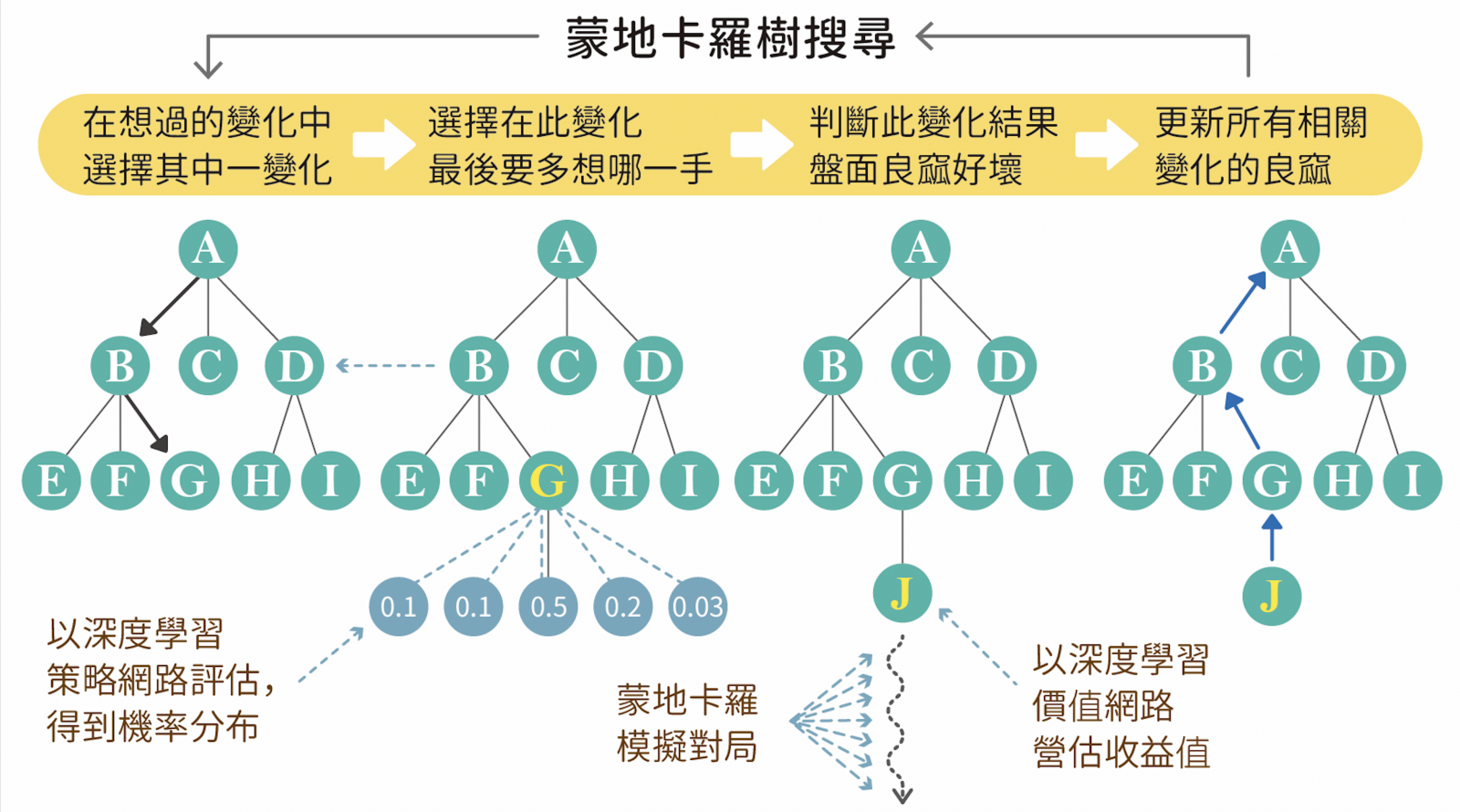
▲圖三:蒙地卡羅樹搜尋。根節點 A 是先選 B,然後 B 節點再選 G。針對 G 產生的子節點,以深度學習策略網路(policy network)評估各種策略,可以得到機率分布為(0.1, 0.1, 0.5, 0.2, 0.03),因此選擇機率值最高的 0.5 的 J 點。根據得到的收益值,更新最佳路徑上所有節點的收益值,次序為 J, G, B, A。
無中生有創造棋步——深度強化式學習
DeepMind 更進一步結合深度學習與強化式學習兩技術,發展出所謂的深度強化式學習技術,並透過此技術自主產生更多優質的棋步,因而得以訓練出精緻的價值網路。基本概念為將每次強化式學習的結果儲存在深度學習網路當中,由於深度學習網路複雜度可以無限提高,因此得以儲存複雜的學習成果。在 2017 年 10 月的 AlphaZero,更是將深度強化式學習的特性發揮到極致,並且可以無中生有,自己產生出超越人類水準的策略網路與價值網路,棋力足以打敗所有的人類高手。實際上,DeepMind 早於 2014 年就成功地運用此技術,能夠一般化地訓練出高水準的雅達利(Atari)電動遊戲 AI。用在 AlphaZero 則是可自主產生優質的棋步,無須再參考專家棋步。對於朝向一般化的人工智慧研究,也是一個重要的里程碑,可說是目前人工智慧的研究中,最讓人期待的部分。
臺灣在 AlphaZero 深度強化式學習技術的研發,也相當有成果。東華大學 AI 團隊一直致力於利用 AlphaZero 的概念,讓對局程式更加全面,並且用於開發新的棋類。新棋類的棋譜品質較不穩定,AlphaZero 可以不需要借助人類知識,便可開發品質優異的對局程式。2019 年開始,臉書 AI 部門與東華大學AI團隊開始研發一套聚合遊戲(PolyGame)的系統,使用者對於任何有興趣的遊戲,只要編輯遊戲規則,聚合遊戲就可以使用深度強化式學習技術,自動產生強大的遊戲程式,可說是延續 AlphaZero 的研究。
AlphaGo 與 AlphaZero 的各種應用
AlphaGo 與 AlphaZero 等系列的成功,不免讓人擔憂電腦是否會取代人腦的問題,事實上,這些架構之下,只能解決特定問題、並不是泛用性的智慧,因此並無與一般人腦競爭的問題。反倒是這種架構可以應用在許多領域,例如 Google 宣稱將使用在醫療問題上。研究人員可以把對病人的醫療當作下棋,而對手是疾病,所有醫療病歷則是棋譜,如此便可將 AlphaGo 的架構與技術使用在解決醫療問題。
而國內將 AlphaGo 與 AlphaZero 的技術,直接運用在電腦對局的相關應用,除了上述的聚合遊戲外,比較成功的例子是東華大學 AI 團隊的研究,已經開發出一套全方位圍棋學習系統(Life-wide Learning Go System),目前每個月全世界約有 1000 萬人次在使用此系統。全方位圍棋學習系統的概念為一種個人化階層式學習與視覺化分析的教學,其中個人化階層式學習(Personalized Ladder Learning)讓每個人都可擁有自己的學習對象,將個人的學習成果不斷提升。
其原理是對於提升強度的最佳學習對象,就算不是該領域中的佼佼者,反而會成為比使用者目前強度高出一個梯度的對象。然而利用傳統演算法卻難以模擬人類在不同階段的表現,以AI圍棋為例,目前一般圍棋程式儘管擁有足以擊敗職業對手的強度,卻對一般大眾的學習無法起到大的幫助。而運用深度學習與強化式學習,便可做到個人化階層式學習系統的建立,由圖四可看出,圍棋可分為入門∕級位∕段位∕職業等階層。純棋則是研究團隊發展的新遊戲,可以簡化圍棋,讓一般人在 10 分鐘內就學會下圍棋。深度學習甚至可以在同一階層提供不同風格的學習對象,目前系統提供攻擊,防守、圍地、破地等四種棋風,可讓學習者與不同個性的對手對弈,建立全方位的階層式學習。
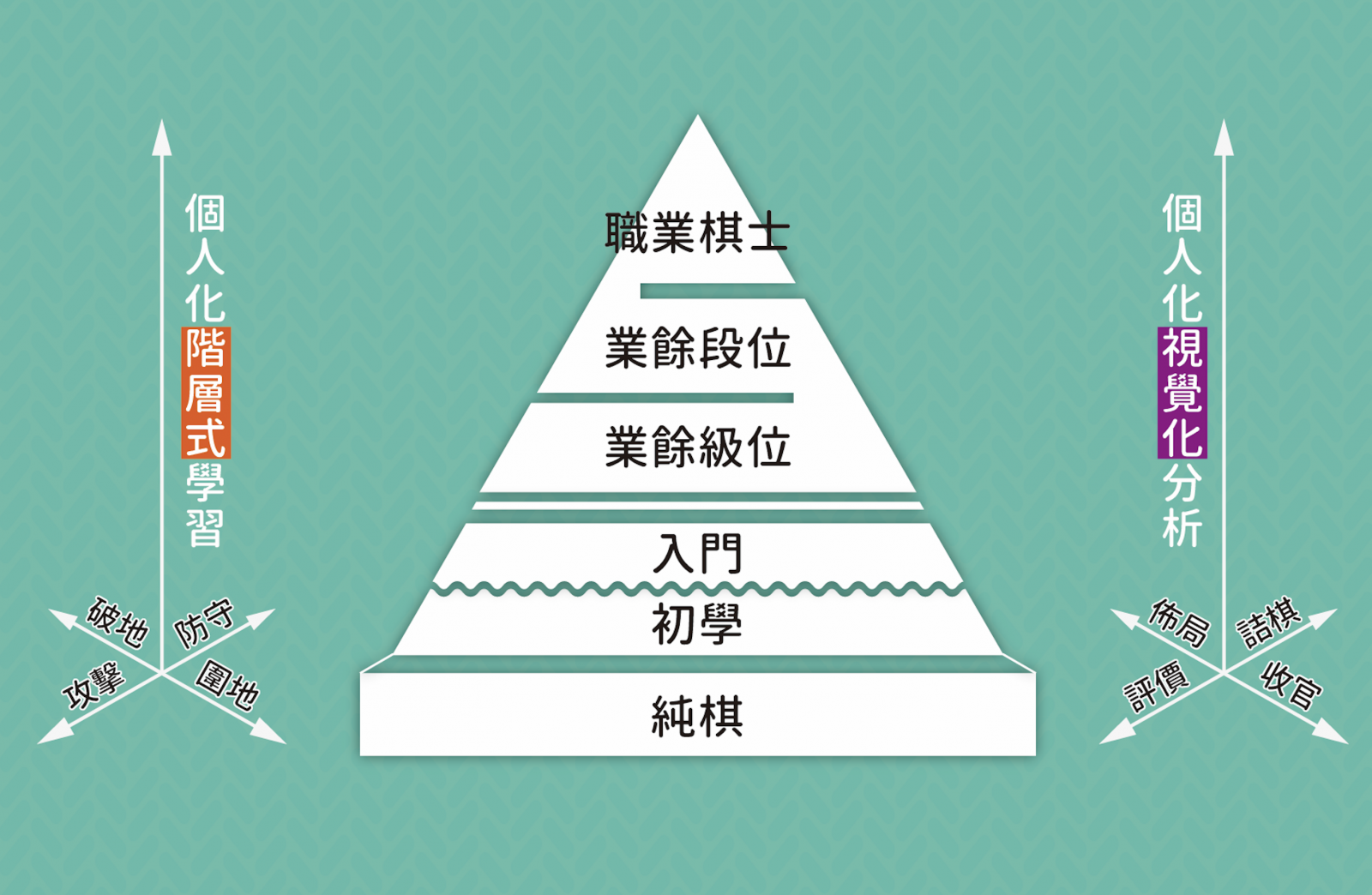
▲圖四:基於 AlphaGo 技術發展的全方位圍棋學習系統。
系統中的個人化視覺化分析(Personalized Visual Learning)是在教學傳遞資訊時,針對每個人當時的狀況,以圖像化、視覺化的方式進行教學,使學習的過程更加直覺而有效率。當學習任何事物的時候,往往會從課本的課文、網路的說明、他人的話語等,獲取抽象的語言資訊,並在腦內加工成具體的圖像與形象,而此過程必須花費許多理解成本。但若能在傳遞資訊時,針對每個人當時的狀況與需求,以圖像化、視覺化的方式,就可以使學習的過程更加直覺、有效率。利用深度學習與強化式學習技術產生教學所需的圖像,範圍涵蓋布局思考、詰棋細算、評價盤面、收官計算(如圖四右側所示),建立全方位的個人化視覺化分析的教學系統。
結語
總結來說,AlphaGo 的深度學習技術可以將整理專家知識的過程自動化,以更精準而有效率的方式吸收專家知識,甚至能無中生有,自動產生比人類專家更厲害的知識。而相關的技術影響將非常深遠,不只是用於擊敗人類棋王的勝利,在相關技術在廣泛應用之後,對人類社會帶來的影響,將是許多技術與服務的提升。目前東華大學 AI 團隊正致力於發展圍棋的階層式與視覺化的 AI 教學服務,將圍棋普及到世界各地。期許後續的研究將使人類整體工作負擔減輕,享受更好的生活品質與服務,並為世界所帶來的正面效益。
⇠上一篇:函數、神經網路與深度學習



