



















蔡炎龍∕政治大學應用數學系副教授。
最近人工智慧非常紅,而深度學習則可以謂人工智慧的核心。那到底深度學習是什麼呢?外面有很多把人工智慧或深度學習的概念說得很玄的文章,但在這篇文章中,則希望讓大家瞭解深度學習的核心概念。你會發現,其實基本概念非常簡單!而人工智慧到底可以做到什麼,其實也和我們的想像力有關。
人工智慧就是學一個函數
這裡說的函數,其實就是數學上所說的函數。你可能會覺得奇怪:學一個函數?學函數能做什麼?我們回想一下函數 f 的定義,就是 2 個集合 X、Y 之間的對應關係。X 是定義域,Y 是值域,每一個 X 裡的元素,都要對應到 Y 裡的一個元素,而且只能對到一個。這樣說明可能會聽不太懂,換句話說,其實一個函數就是我們所關心的某個問題完整的「解答本」,而 X 是所有可能的題目(問題),Y 則是所有可能的答案。函數的定義就是讓所有的題目都要有解答,並且是唯一、明確的答案。
在現實生活中可以說處處有我們想知道的函數,為使大家能更瞭解,以下舉幾個例子:
(1)若想要知道某個英文句子中文翻譯是什麼,則利用「翻譯函數」,X 是所有可能的英文句子,Y 是所有可能的中文句子。那麼這裡的函數就是輸入英文,要輸出中文的翻譯。
f(“How are you?”)=“你好嗎?”
(2)若想知道某支股票在未來某一天會漲或是跌,可以把X設為所有股市開盤的日子(不管是現在、過去或未來),Y 是實數的集合(雖然其實不用設那麼大),設定出的函數就是:
f(某個開盤日 x) = x 當天某股的收盤價
你會發現,要是真的知道這個函數,那就賺翻了!
(3)若有一個交友網,想從裡面的資料中知道某 2 位會員是最速配的,這有很多種建函數的方法,其中一種是 X 是所有可能的會員配對,Y 可能是 0~10 的數字:將 0 定義為完全不來電,10 是完全速配!所呈現函數就會是:
f(X,Y)=X 和 Y 這兩位的速配指數
(4)若要透過建立一個圖形辨識系統,辨識照片裡的鳥是什麼鳥。比方說:
f(一張鳥的照片)=“冠羽畫眉”
利用電腦來分辨照片上分別是什麼品種的鳥。
上述所說的各項例子可以告訴我們,就是把「想知道答案的問題」化成一個函數,如果真能找到這個函數,就可以幫忙解決不管是預測、速配指數還是鳥類辨識等種種問題。而有一個「全能型」的函數學習系統,也就是基本上能化成一個函數的問題,利用一些過去經驗,也就是部分已知「正確答案」的情況下,就可以如魔術般找到此函數的方法,那就是「神經網路」。而神經網路正是深度學習的基本架構!
▲神經網路與深度學習的概念圖。圖片來源/Shutterstock
不過,真正的函數運用還是與上面所舉得例子有一點不同,那就是函數在輸入、輸出時一定要是一個向量,也就是數字。不過,這也不是個問題,就以上面的例子來說,在鳥類辨識中,輸入的是張照片,而數位相片其實就是由一串數字所組成!那輸出為鳥名怎麼辦呢?這也容易,就給各種鳥設定一個編號,比方說冠羽畫眉是 1 號、臺灣藍鵲是 2 號、五色鳥是 3 號等。
對於函數設計而言,真正的問題常常是「問問題的方式」。想要知道某個問題的答案,可以透過許多不同的問法,又或說是由不同的方式切入。要「問得好」常常需要經驗、某個領域的專業知識甚至是創意!這個部份其實意外的重要,對於人類而言,好消息是目前這種「問問題」的工作,電腦是不太容易取代人腦的。既然問完問題,接著就要介紹如魔術般的神經網路,到底是如何找到所需的函數!
神經網路的基本架構
神經網路只是一個建構函數的方式。當我們問了問題,並準備許多歷史資料當做的「考古題」,希望能訓練神經網路看到新的問題時也可以正確回答:比如說鳥類辨識的神經網路在訓練後,可以正確叫出沒看過的鳥名。
其實,神經網路是上個世紀就紅過的東西,後來又没落一陣子。一直到現在,標準神經網路的架構其實沒有什麼改變,而現今所說的深度學習,其實就是「深度」的神經網路。基本的架構就三種,分別是「標準神經網路(Neural Network, NN)」、「捲積神經網路(Convolutional Neural Network, CNN)」及「遞迴神經網路(Recurrent Neural Network, RNN)」。然而,為什麼現在神經網路或是深度學習再度一炮而紅呢?原因是因為現在的電腦能做到比較「深度」,並處理「大量資料」的神經網路。再加上有越來越多例子證明深度學習的優秀,像是 ImageNet 圖形辨識大賽自 2012 年以來,幾乎全是捲積神經網路的天下;AlphaGo 打敗世界棋王,想想以前還有不少人認為圍棋程式要贏職業棋士應該還需要 100 年!
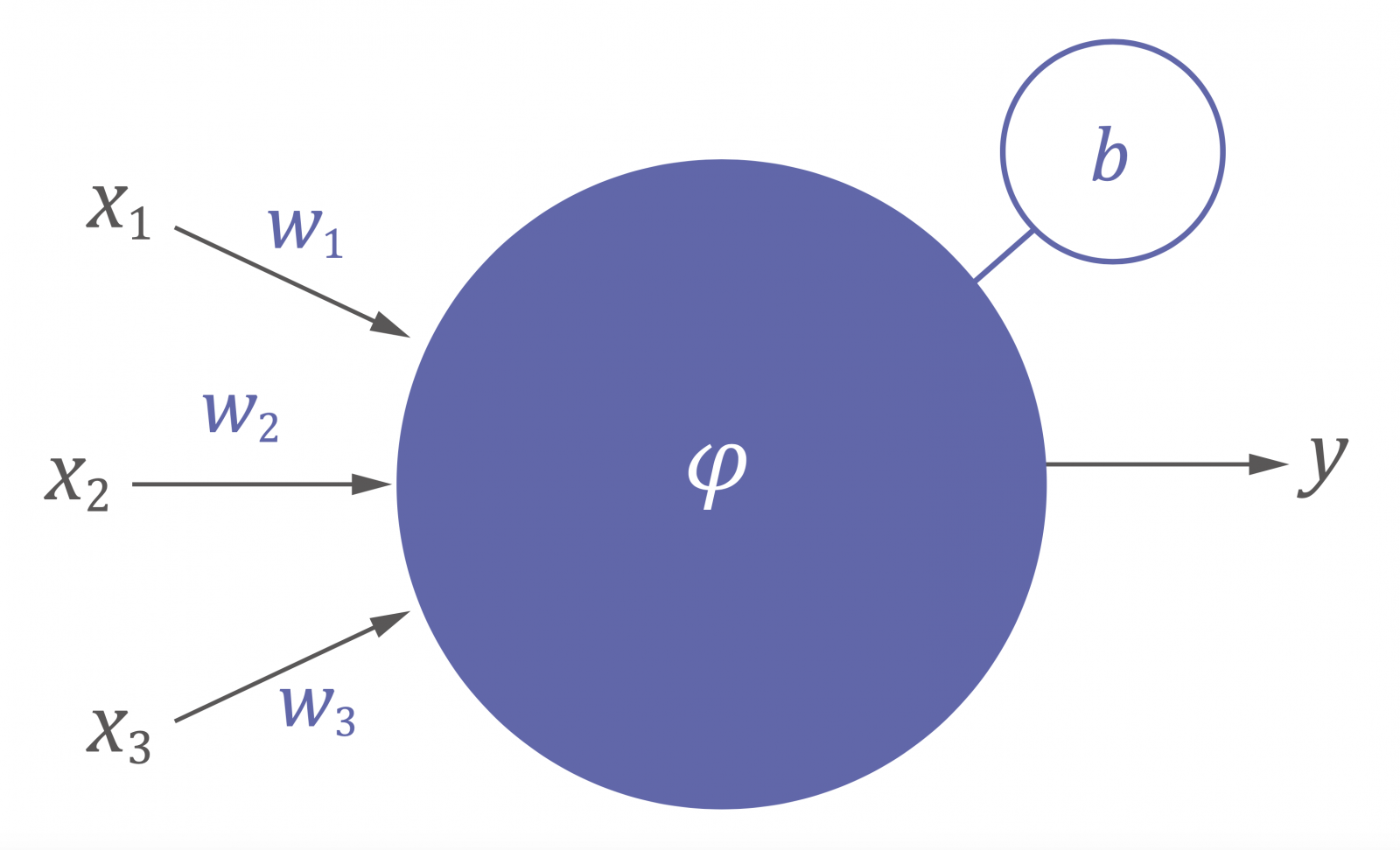
▲圖一:一個「神經元」的基本結構。圖片提供/作者,繪圖/《科學月刊》
神經網路的架構方式其實也不神奇,基本上就是一個個「神經元」組成。最標準的神經元接受(可能)數個輸入值(也就是外來的刺激),然後產生一個輸出。輸出又可能會接到另一個神經元,所以最後會變成很複雜的結構。如圖一是有3個輸入的神經元,輸入時會乘上一個權重(weight),再加上一個偏值(bias),最後再經一個非線性的激發函數(activation function),就決定了這個神經元的輸出。在圖一的例子中,會有 y=φ(w1x1+w2x2+w3x3+b) 這樣的關係。
標準的神經網路一層一層之間是「完全連結」的,捲積神經網路和遞迴神經網路有一些不同的架構,不過每個「神經元」還是大同小異的運作方式。圖二是一個輸入是二維、輸出也是二維的神經網路。中間叫做隱藏層,圖二的例子有 2 個隱藏層,每層各有 3 個神經元,每個神經元都是像之前說明的運作方式運作的。雖然沒有明確的定義,但一般隱藏深層有 3 層或 3 層以上,就會稱為「深度」神經網路。
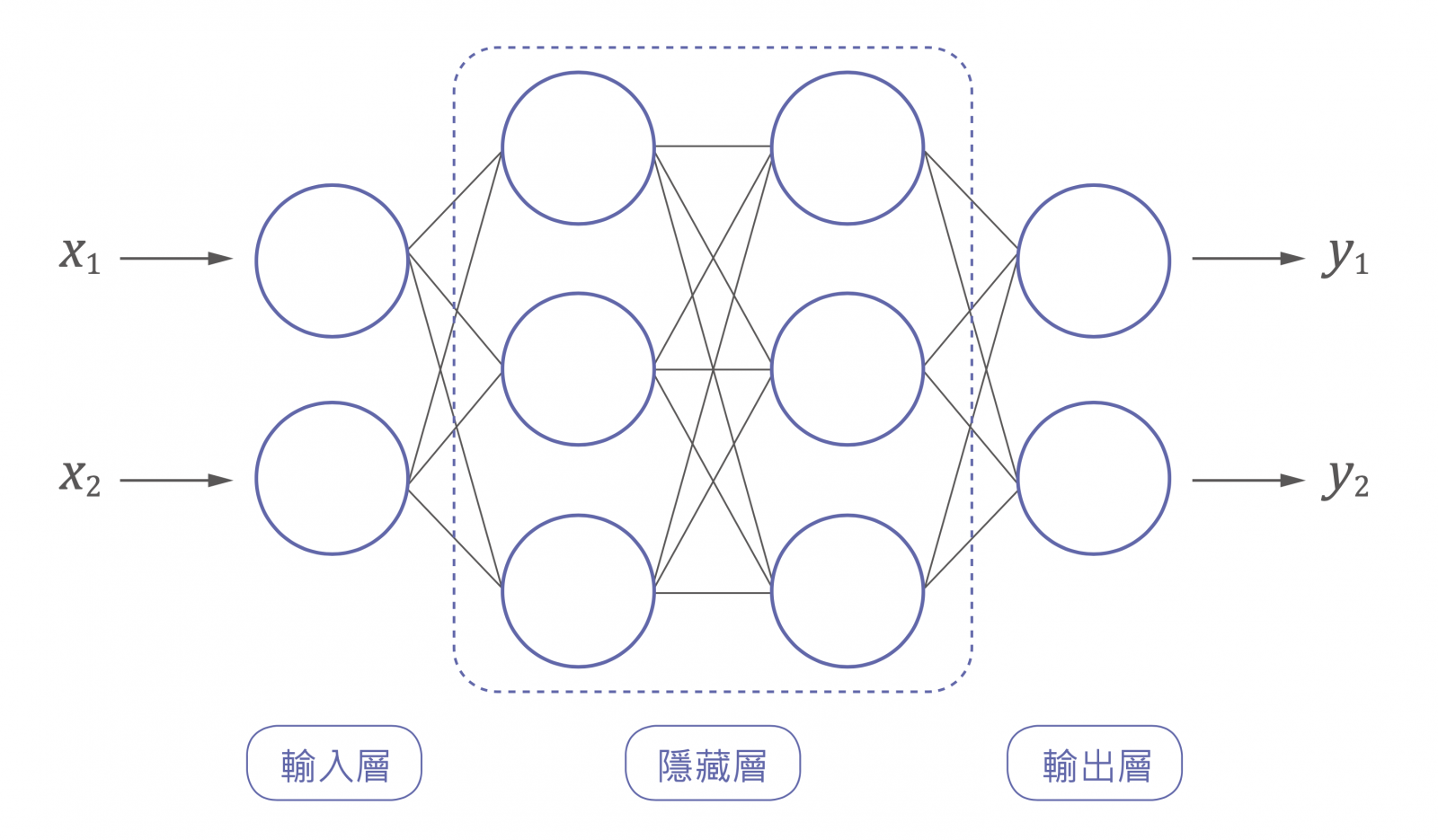
▲圖二:兩層隱藏層的神經網路。圖片提供/作者,繪圖/《科學月刊》
神經網路的學習方式
問完問題、建構好神經網路後,接著就是要「訓練」神經網路。所謂的訓練其實就是拿歷史資料,也就是「考古題」,不斷的餵給神經網路讓它練習。通常一開始神經網路表現很差,但會因學習而慢慢變得越來越好。這看來很神奇的事是如何發生的呢?
原來所謂訓練神經網路,就是去調整每個神經元的權重和偏值。先定義一個損失函數 (loss function, L),來測量和正確答案差多遠。比方說可以定義損失函數的值,是神經網路的輸出值和正確答案的「平均平方差」。損失函數是所有可以調整的參數(就是權重和偏值)的函數:調得好損失函數的值就會變小,反之調不好損失函數的值會變大。
調整這些參數的過程就是神經網路的學習過程,最標準的「學習方式」稱為「梯度下降法(gradient descent)」。為了簡化說明讓大家瞭解,先假設神經網路只有一個參數要調,叫做 w,於是損失函數就是一個變數的函數 L(w)。
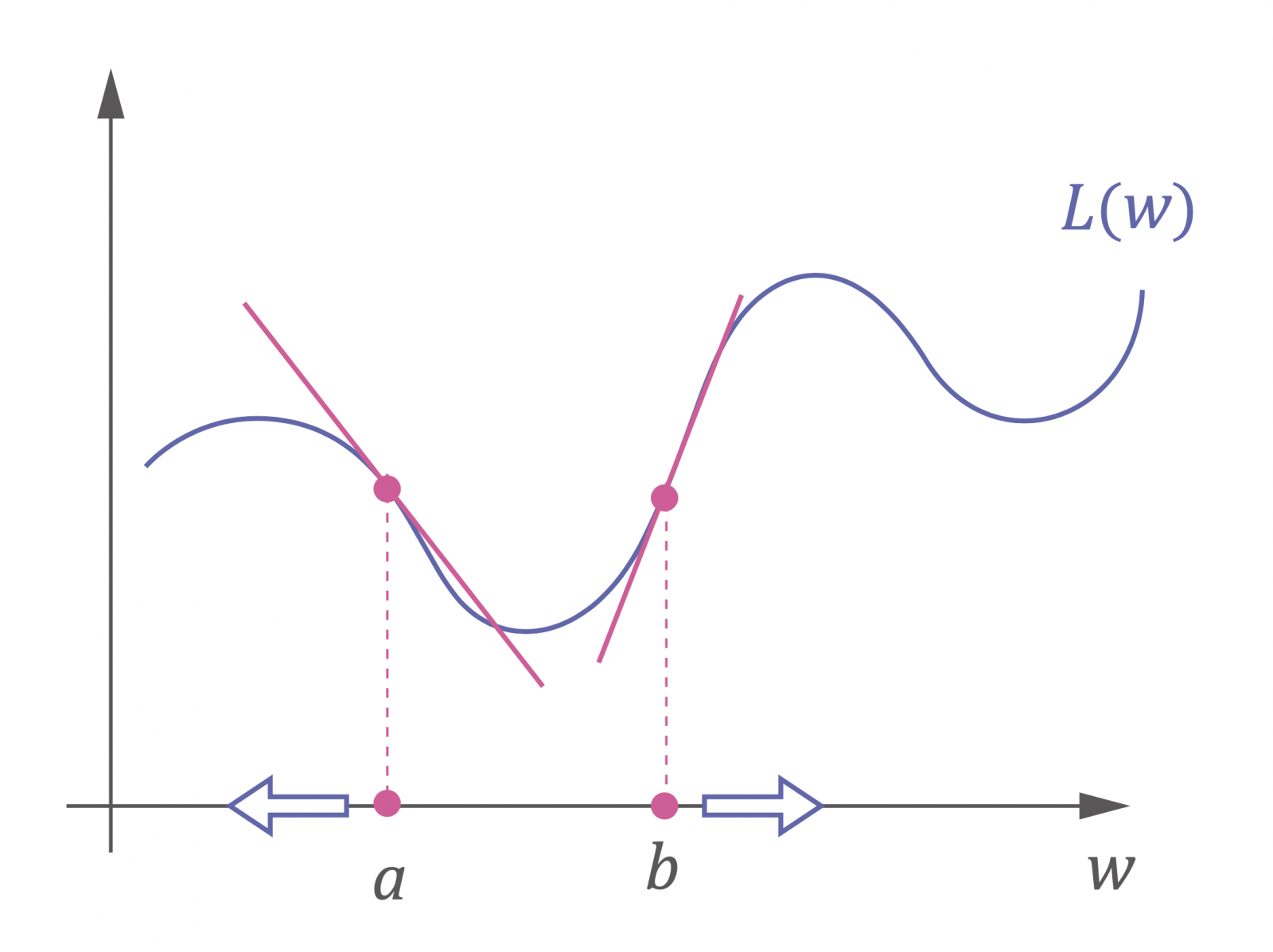
▲圖三:調整權重的方向和切線斜率有關。圖片提供/作者,繪圖/《科學月刊》
我們再來看圖三,假設權重 w 一開始設在 a 點,若希望往讓 L 變小的方向移動,電腦要怎麼判斷呢?用微分求 L 在 a 的導數 L ́(a) ,算出的值就是切線斜率,很明顯在 a 點切線斜率是負的,也就是指的方向是左邊、負的方向。於是只要讓 w 的值往「切線斜率 L ́(a) 的反方向」移動就可以。也就是說,新權重可以這樣設:
w = a−L ́(a)
如果起始點設在 b 點,也是朝切線斜率的反方向走就可以!
最後有一個小問題,那就是每次調切線斜率的大小可能會調太大,也許會「錯過」極小值。於是可以設一個「學習速率(learning rate, η)」,說穿了只是一個很小的數字,比如 0.01,調整每次調整的速度,於是真正調整後的 w 就會變成:
w = a-ηL ́(a)
當然,神經網路的參數不只一個,成百上千都是常有的事。但很令人驚訝的,多變數的情況其實和單變數很接近:最大值的方向是對每個變數求偏微分,也就是 L 這個函數的梯度,符號是 ∇L。只要調整向整個梯度指的反方向走,因此稱做梯度下降法!
關鍵是問個好問題
希望在介紹之後,能讓讀者對人工智慧的原理有了基本的認識,也能發現其實並不複雜和神秘。反而是當要做什麼樣的應用時,有時需要創意的巧思,和對某個領域深入的理解,人工智慧的關鍵,也就在於能不能「問個好問題」。目前,如何問個好問題還是電腦完全無法取代人類的地方,所以,讓我們一起努力,使人工智慧有更多令人興奮的、造福人類的應用產生。
⇠上一篇:人工智慧浪潮下的數學教育



