



















游森棚∕任教於臺灣師範大學數學系及空軍官校。
前陣子與韓國學者聊天,他們說現在在數學界找工作不易,因為什麼都要跟「大數據(big data)」扯上關係。的確,大數據儼然是現在很夯的詞,臺灣的數學系所一共就這麼多,而我知道的就有六、七間打算要成立大數據中心,想要延聘的新人都需要有大數據的背景。
大數據時代
什麼是大數據?顧名思義就是處理極大量資料的一門學問。電腦與網路出現與普及後,大量資料的處理變成新的挑戰。但這不是什麼新鮮的東西,幾十年來,歐洲核子研究組織(European Organization for Nuclear Research, CERN)的高能實驗物理學家早已習慣每秒要處理超過 1 千兆位元組(terabyte, TB)的巨量資料。
然而,現今網路的普及,使 Google、Facebook、LINE 和 Twitter 等社交網路與廣告滲透到每一個人的生活,網路上宏觀的大量數據變得非常有趣。2012 年 12 月 11 日紐約時報有一篇專欄文章,標題是「The Age of Big Data(大數據時代的來臨)」。
TED 的一個演講簡明地介紹了大數據的概念(註一),相當值得一看。現在普遍接受的定義是,大數據處理的資料有四個特點,又稱 4V,分別是多(volumn)、快(velocity)、雜(variety)與真偽難辨(veracity)。面對一堆資料,如何處理、如何擷取出有用的部分、如何分析相關性、找到模式並預測趨勢等,這些大概就是大數據要做的事。
以上的解釋都是概念性的,說實在還是很模糊。關於細節我不是專家,也無法深談。不過最關鍵的是,這些和數學有什麼關係呢?底下舉2個我覺得有趣的例子。第一個例子講要發展大數據背後真的需要高深的數學,第二個例子是用大數據分析後最近得到的意外結果。
搜尋引擎系統
第一個是 Google 的搜尋引擎的運作。網路上有上千億個網頁,Google 搜尋的強項就是它能很快找到有用的網頁,而關鍵就是把網頁排序。以下的例子擷取自布基亞尼科(Bucchianico)的演講稿,假設只有四個網頁,互相連結的樣子如圖一。網頁 1 會超連結到網頁 2、3、4(不妨各給權重 1/3),網頁 2 超連結到網頁 3、4(各給權重 1/2),以此類推。
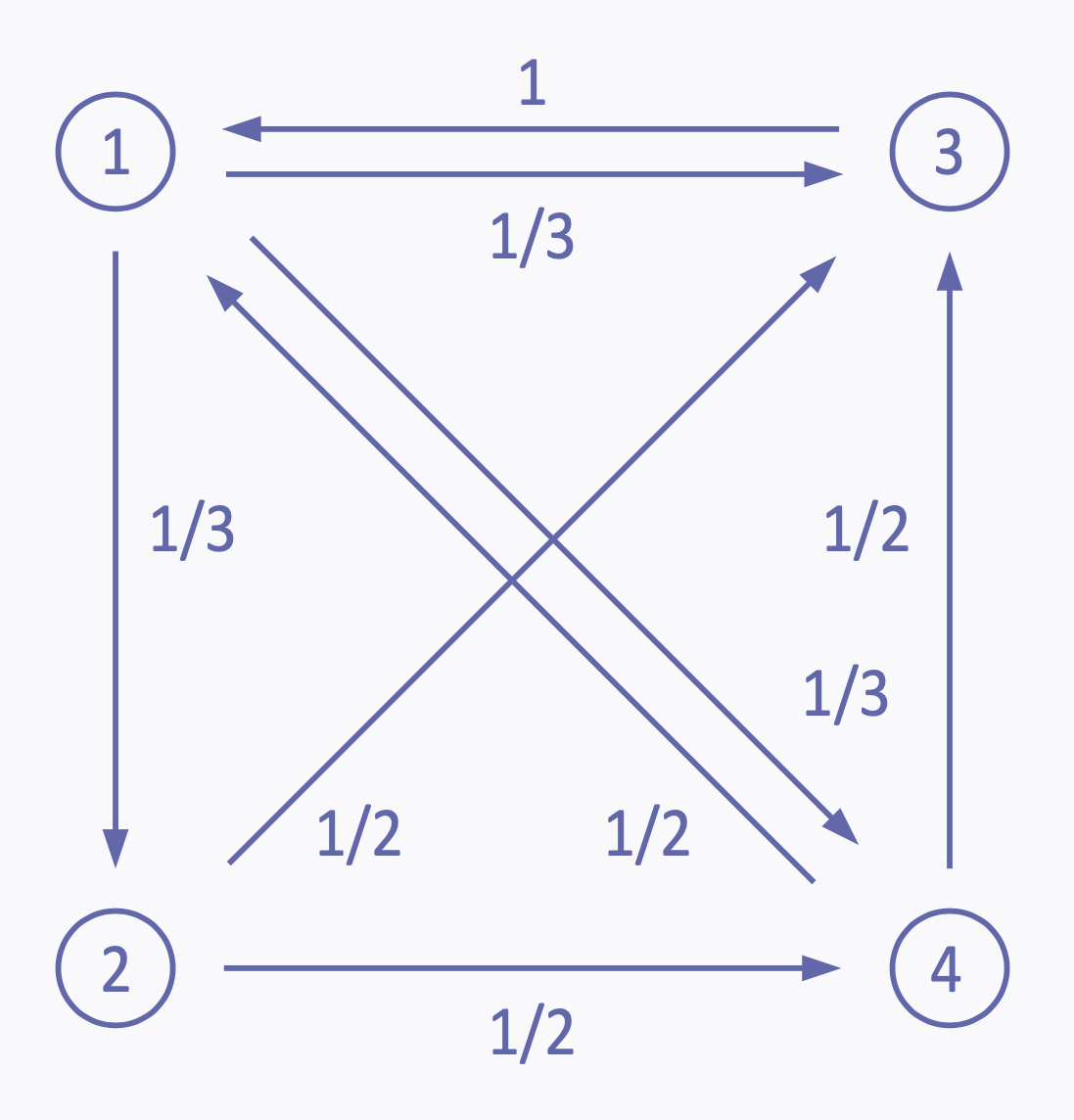
▲圖一
因此,這 4 個網頁互相參照的關係就可以寫成以下的聯立方程組:
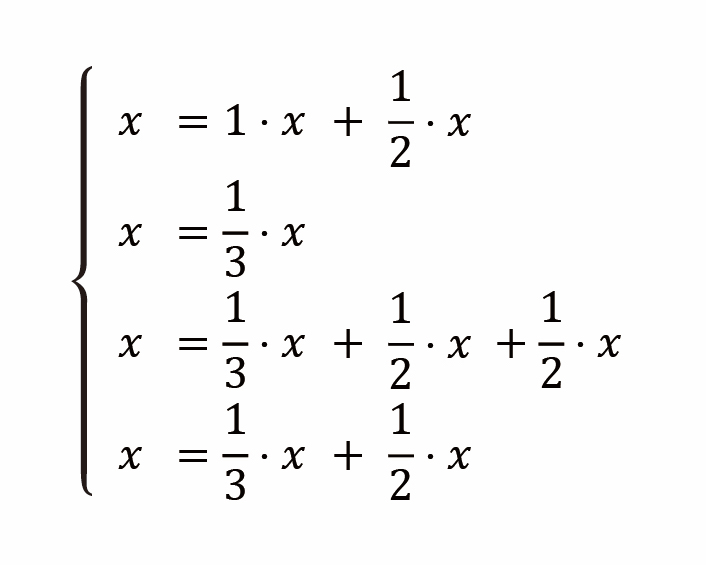
寫成矩陣的樣子就變成:

可以解得:
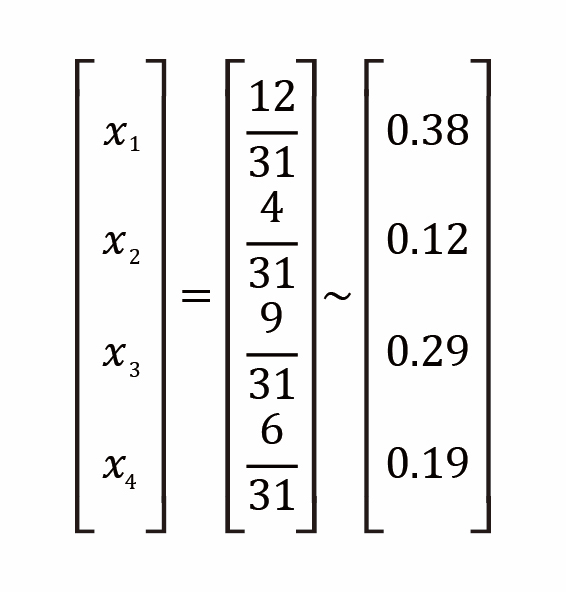
也就是說,網頁 1 最重要(0.38),然後依序是網頁 3、網頁 4 與網頁 2。
如同上例,一個網頁代表一個行與列,現今網頁約有三百億個,所以真實世界中,Google 要計算的是一個 300×300 億的超級大矩陣,更不要說每天還會新增加數十萬個新網頁。雖然說這個超大矩陣有非常多的 0(多半的網頁是不會互相有超連結的)但是這個矩陣太巨大,要做計算不只需要電腦,還需要高深的數學才有辦法。數學,就在這種地方出現了。
縱橫字謎
第二個例子非常小眾,但頗為有趣。縱橫字謎(crossword)是美國流行的看提示填單字的填字遊戲,也是我個人平常的消遣。要玩縱橫字謎除了需要字彙能力,還要不少文化知識與瑣碎事實,再加上一點想像力與幽默感。縱橫字謎發展到現在已經高度專業,最好的字謎公認是紐約時報。除了已經告知是最難等級的字謎之外,每個字謎會有一個主題(theme),通常出現在整個字謎答案中最長的那幾個字,有一些內在的聯繫。底下舉一個例子讓讀者瞭解,2001 年 1 月 8 日紐約時報刊出的字謎作者是保羅(George E. Paul),答案如圖二。

▲圖二
這個字謎的主題出現在:
1. 橫 20:Drive up the wall(使人大怒)。
2. 橫 38:Get on one's nerve(激怒某人)。
3. 橫 53:Rub the wrong way(惹人生氣)。
這三個主題字妙在三個都是「激怒」的意思,而且字面上和開車有關「drive up、get on、wrong way( 上路、上車、走錯路)」。解字謎時主題不會先透露,需要慢慢解出其他位置,拼湊出主題後才有恍然大悟的快感。
講這麼多就是要說明,主題是一個字謎的靈魂,是一個字謎的身份證。對於創作者來說,想出一個好主題並不容易,是智慧的結晶。但解字謎對於愛好者來說就像解數獨,每天都有新的,解過就扔了。但大數據則是分析海量資料,前幾年,有人把美國數十家主要報紙從一開始有字謎到現在,數十年中每一天的字謎全建成資料庫,然後分析這個資料庫,做交叉比對、語料分析和詞彙頻率分析等。
讓「字謎創作者」這個非常小眾的圈子譁然的現象出現了,大數據分析後,發現《今日美國》(USA Today)報紙的部分字謎非常詭異,比如上述字謎,完全一樣的三個主題字出現在 2010 年 6 月 4 日《今日美國》的字謎中。
1、2 個字謎主題相似也許是巧合,但是當分析顯示有數百個字謎都有類似的狀況,這就不是偶然,而是是明顯的抄襲了。這些抄襲的字謎都是在《今日美國》的字謎編輯帕克任內發生的。這個由大量數據分析出來的鐵證讓帕克被轟下台,黯然去職。我想,帕克應該怎麼也不會想到這種用過即丟的東西,會有人真的能抓出來某個字謎抄襲了十年前的字謎。這個不靠電腦大數據分析,還真的做不到。
結語
大數據這個領域不只新,而且剛起步,機會看來是很多。這個領域真正的專家,麻省理工學院(Massachusetts Institute of Technology, MIT)的超級電腦中心主任開普納(Jeremy Kepler)教授所寫的第一本大數據與數學的專著Mathematics of Big Data: Spreadsheets, Databases, Matrices, and Graphs才剛剛出版而已。然而,學術的累積很難一蹴可幾,只希望大數據在臺灣或數學界的熱潮不是一窩蜂的跟風,要真的能看到能夠深化經營的點與方向,才能有一席之地與長久的發展。
註一:大數據的概念:https://bit.ly/1C0mEaE。
⇠上一篇:「數大」便是美——大數據與現代生活的連結
未來金融的新面向——區塊鏈:下一篇⇢



